En más de tres siglos de ciencia todo ha cambiado excepto tal vez una cosa: el amor por lo simple. - Jorge Wagensberg
Mostrar Código
import arviz as azimport pymc as pmimport numpy as npimport pandas as pdimport preliz as pzfrom scipy.stats import linregressfrom scipy.special import expit as logisticfrom scipy.interpolate import PchipInterpolatorimport matplotlib.pyplot as pltimport xarray as xrimport warningswarnings.simplefilter(action='ignore', category=FutureWarning)
Mostrar Código
plt.style.use('arviz-doc')
La música, ya sea la Suite para violonchelo N° 1 de Bach, el pibe cantina de damas gratis o Libertango de Piazzolla, se construye con patrones recurrentes. Las mismas escalas, progressiones de acordes, riffs, etc. aparecen una y otra vez dando lugar a un maravilloso paisaje sonoro capaz de provocar y modular toda la gama de emociones humanas. De manera similar, el universo estadístico está compuesto de patrones recurrentes, pequeños motivos que aparecen una y otra vez. En este capítulo, vamos a ver uno de los más populares y útiles de ellos, el modelo lineal. Este es un modelo muy útil en sí mismo y también el componente básico de muchos otros modelos. Es probable que algunos de los siguientes términos te resulten familiares: regresión lineal simple, regresión múltiple, regresión logística, ANOVA, ANCOVA. Todos estos métodos son variaciones del mismo motivo subyacente, el modelo de regresión lineal. En este capítulo, cubriremos los siguientes temas:
Regresión lineal simple
Regresión lineal robusta
Regresión jerárquica
Regresión polinomial
Regresión múltiple
Interacciones
Varianza variable
Supongamos que tenemos una variable \(X\), y a partir de esta queremos predecir o modelar una variable \(Y\). Además, estás variables se encuentran apareadas \(\{(x_1,y_1), (x_2,y_2), \dots (x_n,y_n)\}\). En el caso más simple \(X\) e \(Y\) son variables aleatorias continuas y unidimensionales, usando un lenguaje de programación, como Python, las representaríamos usando arrays de dimensión 1 y de tipo flotante.
Las variable \(Y\) suele recibir distintos nombres como variable dependiente, predicha o respuesta, mientras que \(X\) recibe nombres como variable independiente, predictora o de entrada. En Machine learning es común hablar de features en vez de variables y es común pensar que una regresión lineal es un ejemplo de aprendizaje supervisado.
Algunas situaciones típicas en las que se pueden utilizar modelos de regresión lineal:
Modelar la relación entre la salinidad del suelo y la productividad de los cultivos. Luego, responder preguntas como: ¿Es la relación lineal? ¿Qué tan fuerte es esta relación?
Encontrar una relación entre el consumo promedio de chocolate por país y el número de premios Nobel en ese país, y luego comprender por qué esta relación es probablemente espuria.
Predecir la factura de gas de una casa utilizando la radiación solar del informe meteorológico local. ¿Qué tan precisa es esta predicción?
6.1 La idea central en regresión lineal
En un capítulo previo vimos el modelo normal, que (omitiendo las distribuciones a priori) definimos como:
\[
Y \sim \mathcal{N}(\mu, \sigma)
\]
La idea central de la regresión lineal es extender este modelo, agregando una variable predictora \(X\) a la estimación de la media \(\mu\):
\[
\begin{aligned}
\mu = \alpha + \beta X \\
Y &\sim \mathcal{N}(\mu, \sigma)
\end{aligned}
\]
Este modelo dice que existe una relación lineal entre la variable \(X\) y la variable \(Y\). Pero esa relación no es determinista, debido al término de ruido \(\sigma\). Además, el modelo dice que la media de \(Y\) es una función lineal de \(X\), con intercepto\(\alpha\) y pendiente\(\beta\). El intercepto nos dice el valor de \(Y\) cuando \(X=0\), la pendiente nos dice el cambio en \(Y\) por unidad de cambio en \(X\). Debido a que no conocemos los valores de \(\alpha\), \(\beta\) o \(\sigma\), debmos determinar una distribución a priori para estos parámetros.
Una suposición típica cuando se establecen priors para modelos lineales es suponer que son independientes. Esta suposición simplifica enormemente la elección de priors, ya que en vez de definir una dristribución conjunta para los 3 parámetros, podemos definir 3 distribuciones por separado. Al menos en principio, \(\alpha\) y \(\beta\) pueden tomar cualquier valor en los reales, por lo que es común usar a prioris normales para ellos. En cambio \(\sigma\) debe ser un número positivo, por lo que es común usar distribuciónes como seminormal, exponencial, gamma-inversa, etc.
Los valores que puede tomar el intercepto pueden variar mucho de un problema a otro. Por ejemplo, yo solía trabajar con problemas donde era esperable que \(\alpha\) estuviera alrededor de cero y con una desviación estándar muy por debajo de 1. Pero esta experiencia (casi anecdótica) es dificil de trasladar a cualquier otro problema. Con respecto a la pendiente (\(\beta\)), puede ser más fácil tener una noción informada. Usualmente tenemos una idea del signo de la pendiente, por ejemplo esperamos que el peso de un animal aumente, en promedio, con la variable largo (o altura). Para \(\sigma\), podemos establecerlo en un valor grande en la escala de la variable \(Y\), por ejemplo, 2 veces el valor de su desviación estándar. Debemos tener cuidado al usar los datos observados para estimar a prioris, por lo general, está bien si los datos se usan para evitar el uso de a prioris muy restrictivos. Si no tenemos demasiado conocimiento del parámetro, tiene sentido asegurarse que la distribución a priori sea realmente vaga. En cambio, si queremos definir distribuciones a priori más informativas, entonces no deberíamos obtener esa información de los datos observados, sino que deberíamos obtenerla de nuestro conocimiento del dominio.
6.2 Bicicletas lineales
Ahora que tenemos una idea general de cómo luce un modelo lineal Bayesiano, tratemos de cimentar esta idea con un ejemplo.
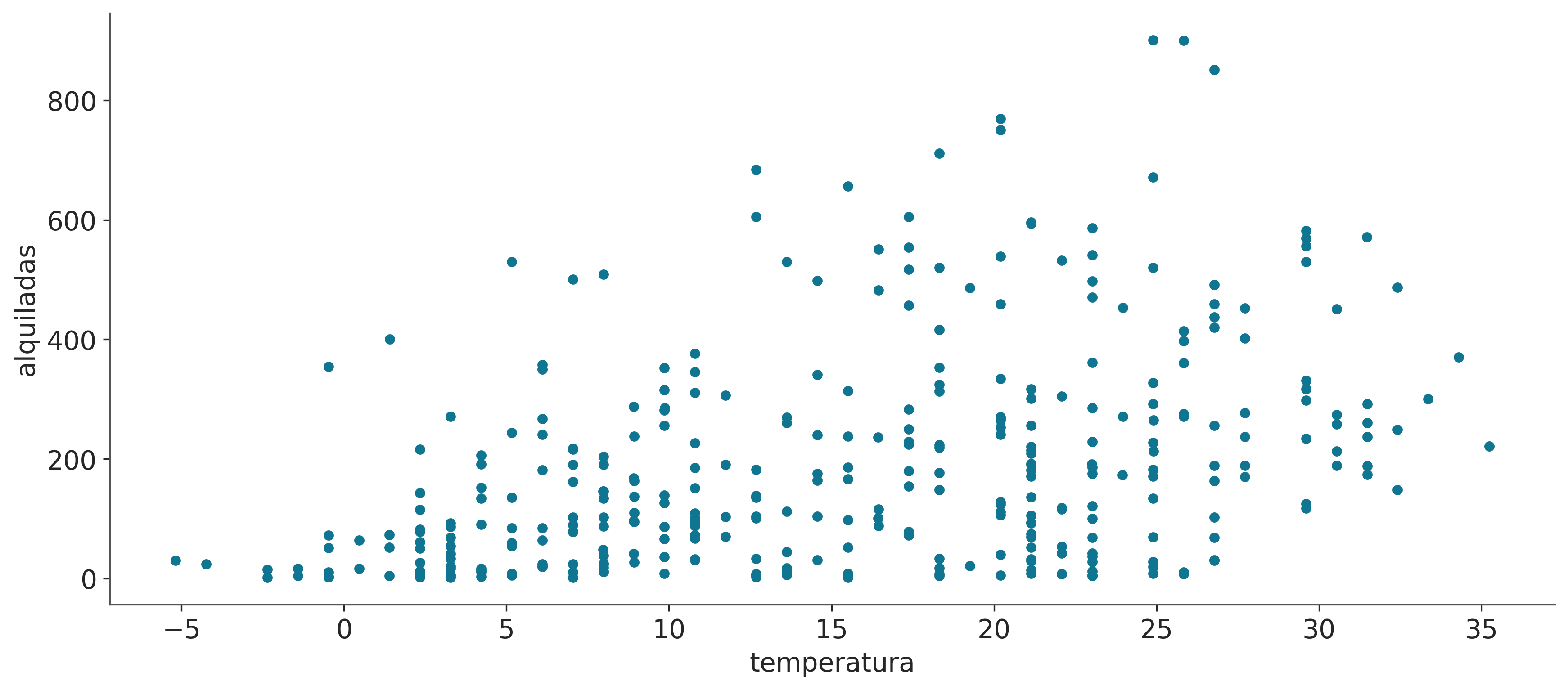
Vamos a empezar muy sencillo, tenemos un registro de temperaturas y del número de bicicletas alquiladas en una ciudad. Queremos modelar la relación entre la temperatura y el número de bicicletas alquiladas. Usaremos bike-sharing dataset del repositorio UCI Machine Learning Repository. El conjunto de datos original contiene 17379 registros, cada registro tiene 17 variables, pero para este ejemplo usaremos tan solo 348 registros y dos variables temperatura y alquiladas. La variable ‘temperatura’ es la temperatura en Celsius y ‘alquiladas’ es el número de bicicletas alquiladas.
Construyamos un modelo lineal bayesiano para estos datos. La temperatura será nuestra variable independiente (nuestra “X”) y el número de bicicletas alquiladas será nuestra variable dependiente (nuestra “Y”). Vamos a utilizar el siguiente modelo:
Antes de calcular la distribución a posteriori tomemos un momento para leer el código línea por línea y asegurarnos de entender lo que está pasando. Comparemos el código con la representación visual del modelo.
Como ya dijimos, este modelo es similar a un modelo normal, la diferenciea principal es que la media se modela como una función lineal de la temperatura. El intercepto es \(\alpha\) y la pendiente es \(\beta\). El término de ruido es \(\sigma\) y la media es \(\mu\).
Algo importante a notar es que la variable \(\mu\) es una variable determinista (pm.Deterministic). Le llamamos así ya que una vez conocidos los valores de \(\alpha\) y \(\beta\), el valor de \(\mu\) queda determinado. En vez que μ = pm.Deterministic('μ', α + β * bikes.temperatura) podríamos haber escrito μ = α + β * bicicletas.temperatura o incluso _ = pm.Normal('y_pred', mu=α + β * bicicletas.temperatura, sigma=ϵ, observado=bicicletas.alquiladas) y el modelo sería el mismo. La única razón de usar pm.Deterministic, es que de esta forma le pedimos a PyMC que guarde los valores de \(\mu\) en el InferenceData.
with modelo_bl: idata_bl = pm.sample(random_seed=123)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [α, β, σ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 3 seconds.
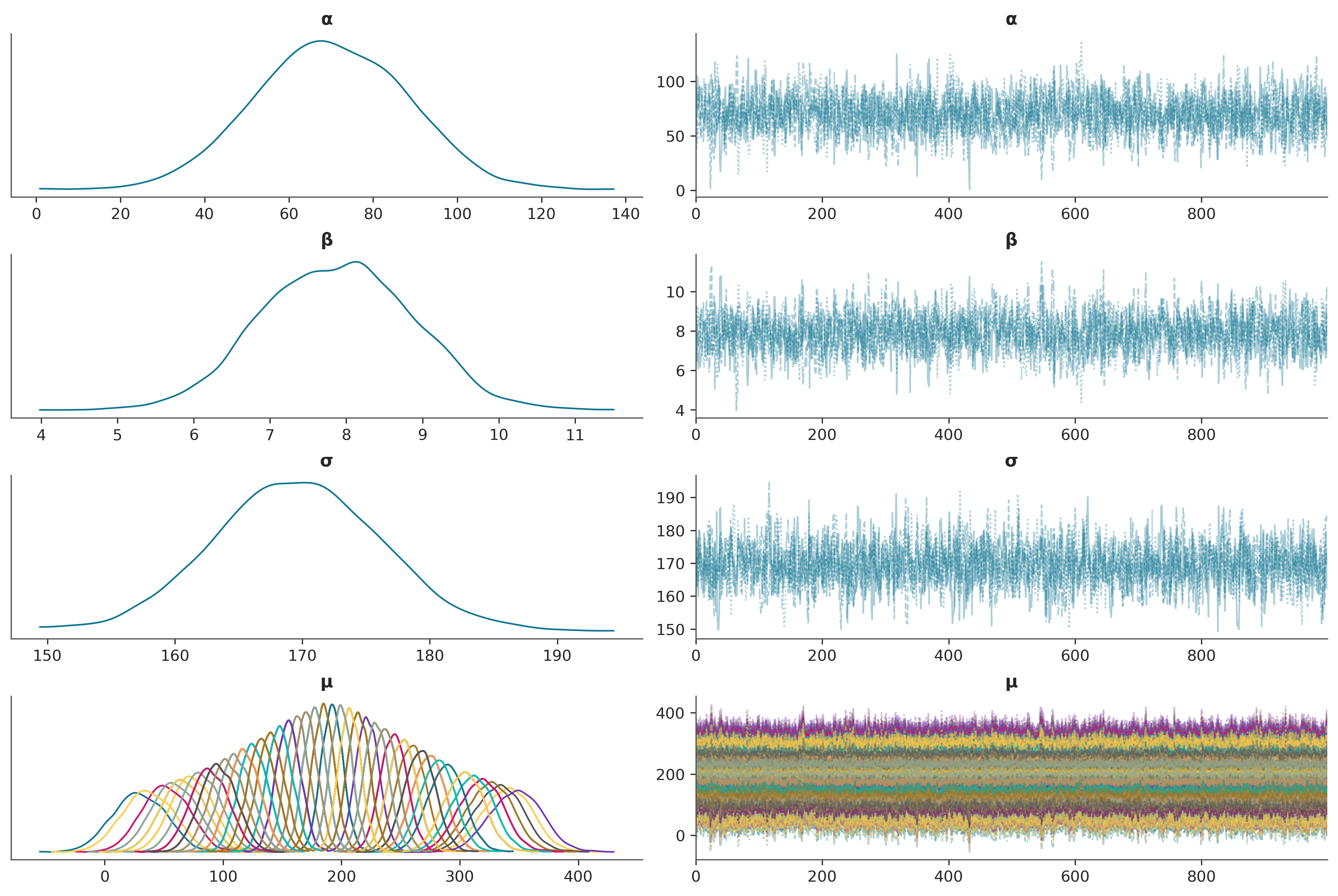
Veamos un trace plot de idata_bl combinando todas las cadenas en una sola curva
az.plot_trace(idata_bl, combined=True);
Algo que suele resultar confuso o inesperado para muchos estudiantes es la gráfica para \(\mu\), por qué hay tantas curvas? Porque a cada observaciones le corresponde una curva, para cáda valor de \(X\), hacemos
\[
\mu_i = \alpha + \beta + x_i
\]
Es decir un valor de \(\mu\) por cada valor de \(X\), además como \(\alpha\) y \(\beta\) son distribuciones. Entonces cada \(\mu_i\) es también una distribución.
Podemos comprobar que hay 348 distribuciones para \(\mu\) inspeccionado el InfereceData, por ejemplo:
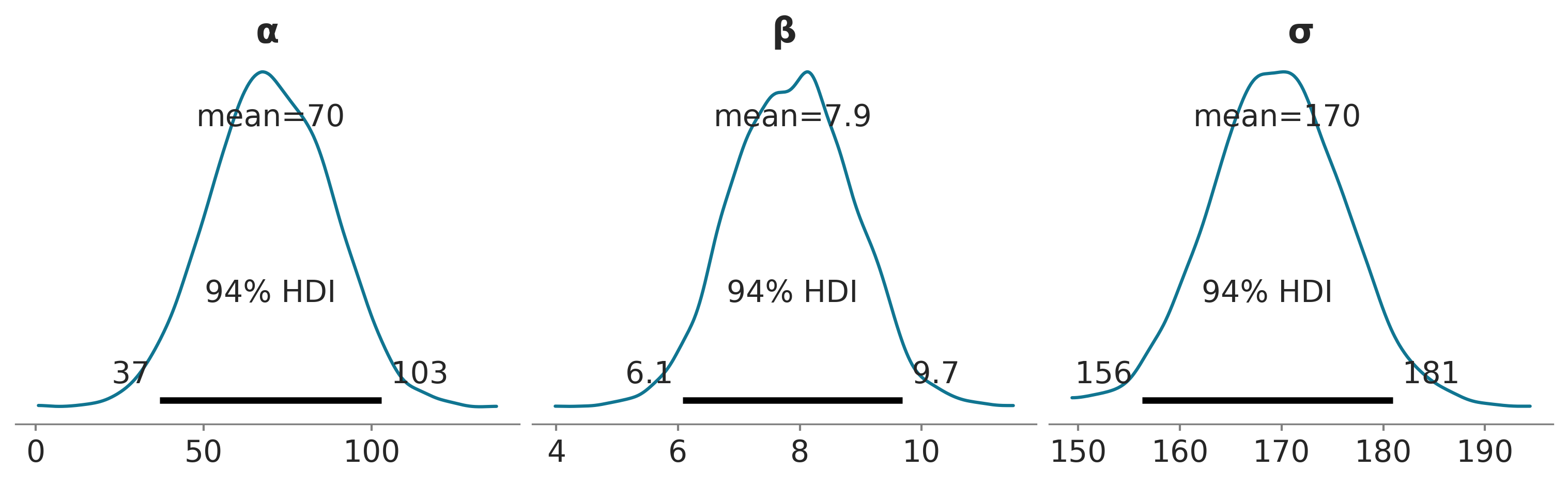
Habiendo aclarado este punto vamos a focalizarnos en intepretar los parámetros del modelo, pero omitiendo μ. Hagamos un gráfico de las distribuciones a posteriori marginales para \(\alpha\), \(\beta\) y \(\sigma\),
Si solo leemos las medias de cada distribución podemos decir que \(\mu = 69 + 7,9 X\). Con esta información podemos decir que el valor esperado de bicicletas alquiladas cuando la temperatura es 0 es de 69 y por cada grado de temperatura el número de bicicletas alquiladas aumenta en 7,9. Así que para una temperatura de 28 grados esperamos alquilar \(69 + 7.9 * 28 \approx 278\) bicicletas. Este es nuestro valor esperado, pero la distribución a posteriori también nos informa sobre la incertidumbre en torno a esta estimación. Por ejemplo, el HDI 94% para \(\beta\) es (6,1, 9,7), por lo que por cada grado de temperatura el número de bicicletas alquiladas podría aumentar de 6 a unas 10.
Incluso si omitimos la incertidumbre a posteriori, y solo prestaramos atención a las medias, tenemos incertidumbre sobre el número de bicicletas alquiladas debido al valor de \(\sigma\) de 170. Entonces, si decimos que para una temperatura de 28 grados, esperamos alquilar 278 bicicletas, no debería sorprendernos que el número real resulte estar entre \(\approx 100\) y \(\approx 500\) bicicletas.
Ahora vamos a crear algunas gráficas que nos ayudarán a visualizar la incertidumbre combinada de estos parámetros. En una primer lectura recomiendo saltearse el código y focalizarse en las figuras y su interpretación.
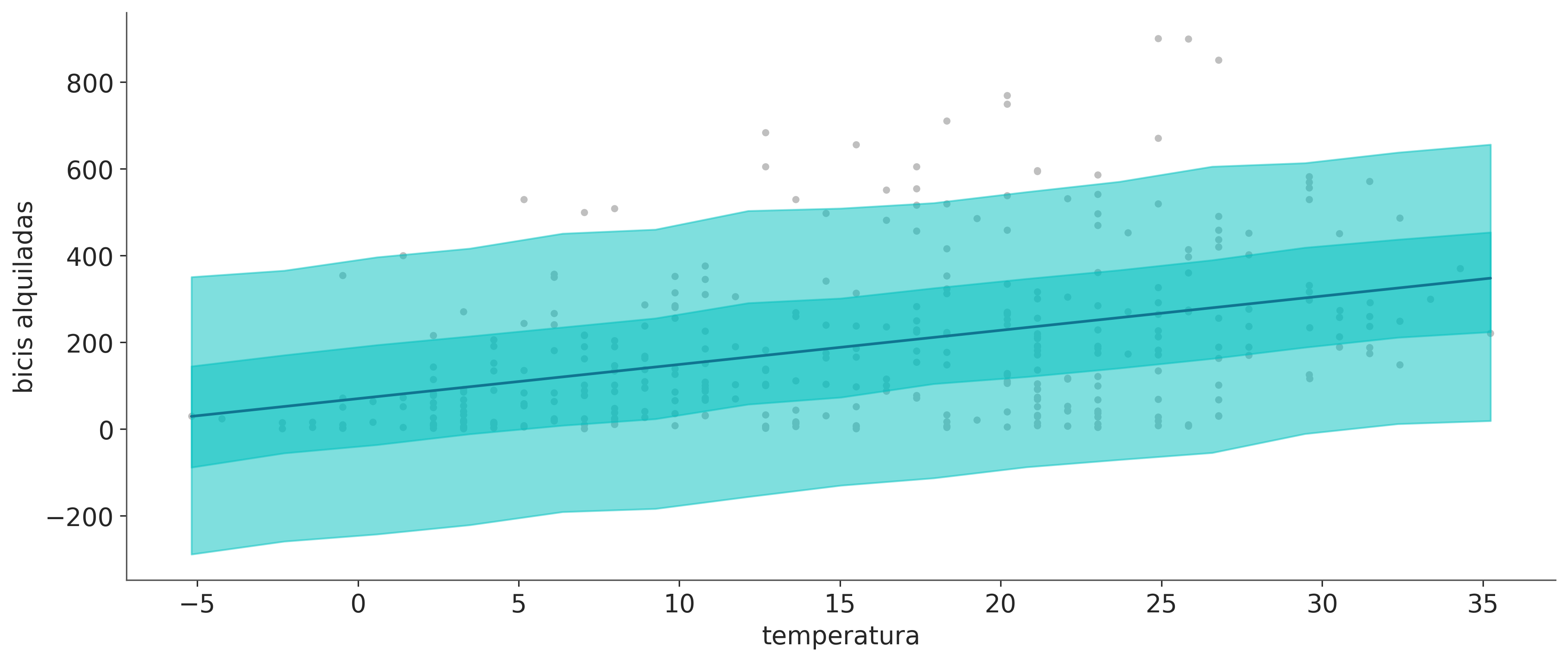
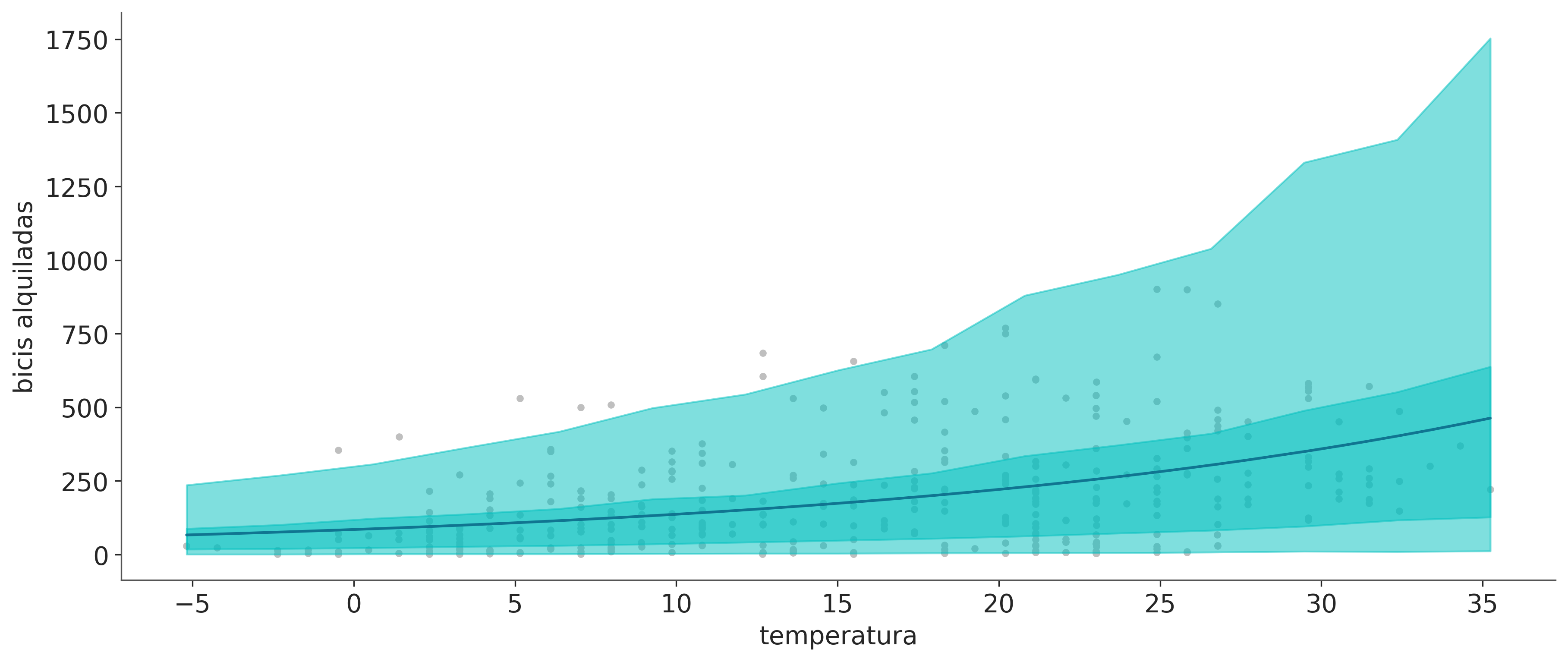
La siguiente figura tiene dos paneles. Ambos muestran del número medio de bicicletas alquiladas en función de la temperatura. La diferencia está en como se representa la incertidumbre. Para el panel izquierdo, tomamos 50 muestras de la distribución a posteriori de \(\mu\) y las dibujamos como líneas individuales. Para el panel derecho tomamos todas las muestras a posteriori de \(\mu\) y las usamos para calcular el HDI 94%.
Ambos paneles transmiten esencialmente la misma información, si volvemos a correr el código para generar el gráfico, las lineas serán diferentes, porque las 50 muestras serán distintas cada vez (salvo que fijemos una semilla). Sin embargo, el área sombreada será la misma, porque estamos utilizando todas las muestras ya calculadas. Si reajustamos el modelo (sin fijar una semillar), no solo obtendremos líneas diferentes, sino que el área sombreada también podría cambiar, pero la diferencia debería ser muy pequeña, caso contrario es probable que necesitemos más muestras (incrementar la candidad de draws en pm.sample(.))
OK, pero ¿Por qué mostramos dos gráficos ligeramente diferentes si transmiten la misma información? Bueno, por un lado para resaltar que hay diferentes formas de representar la incertidumbre. ¿Cuál es mejor? Como de costumbre, eso depende del contexto, el área sombreada es una buena opción, es muy común y es simple de calcular e interpretar. Pero pueden darse situaciones donde nos interese mostrar muestras individuales de la distribución a posteriori, por ejemplo, la mayoría de las líneas podrían abarcar una determinada región, pero algunas podrían tener una pendiente muy alta. Un área sombreada podría opacar esta información. Al mostrar muestras individuales, puede ser una buena idea animarlas si las está mostrando en una presentación o en un video (ver Hypothetical Outcome Plots para obtener más información al respecto).
Otra razón para mostrar estas figuras es que vean diferentes formas de extraer información de la distribución a posteriori. Si prestamos atención al código veremos que en la primera línea usamos az.extract toma la dimensión chain y draw y las apila en una sola dimensión sample, que puede ser útil para el procesamiento posterior. Además, usamos el argumento num_samples para solicitar una submuestra de la distribución a posteriori. Por defecto az.extract opera sobre el grupo posterior de un InferenceData. Si deseamos extraer información de otro grupo, podemos usar el argumento group. En la segunda línea, definimos un DataArray llamado x_plot, con valores igualmente espaciados empezando por la temperatura mínima observada y terminado en la máxima observada. La razón para crear un DataArray es poder usar las capacidades de alineación automática de Xarray (esto lo hacemos en las próximas dos líneas). Si usaramos un arreglo NumPy necesitariamos agregar dimensiones adicionales, lo que puede resultar confuso, la mejor manera de entender completamente lo que quiero decir es definir x_plot = np.linspace(bikes.temperature.min(), bikes.temperature.max()) e intentar rehacer el gráfico. En la tercer y cuarta línea de código, calculamos la media del posterior de \(\mu\) para cada valor de x_plot las líneas individuales, respectivamente. Podríamos haber usado posterior['μ'], pero en su lugar reescribimos explícitamente el modelo lineal, lo hacemos para ser explícitos y con la esperanza de que te ayude a obtener más intuición sobre los modelos lineales.
6.2.2 Interpretando las predicciones a posteriori
¿Qué pasa si no solo estamos interesados en el valor esperado (promedio), sino que queremos pensar en términos de predicciones, es decir, en términos de bicicletas alquiladas? Bueno, para eso podemos usar la distribución predictiva a posteriori. Después de ejecutar la siguiente línea de código idata_lb contendrá un nuevo grupo posterior_predictive con una variable y_pred que representa la distribución predictiva a posteriori para el número de bicicletas alquiladas.
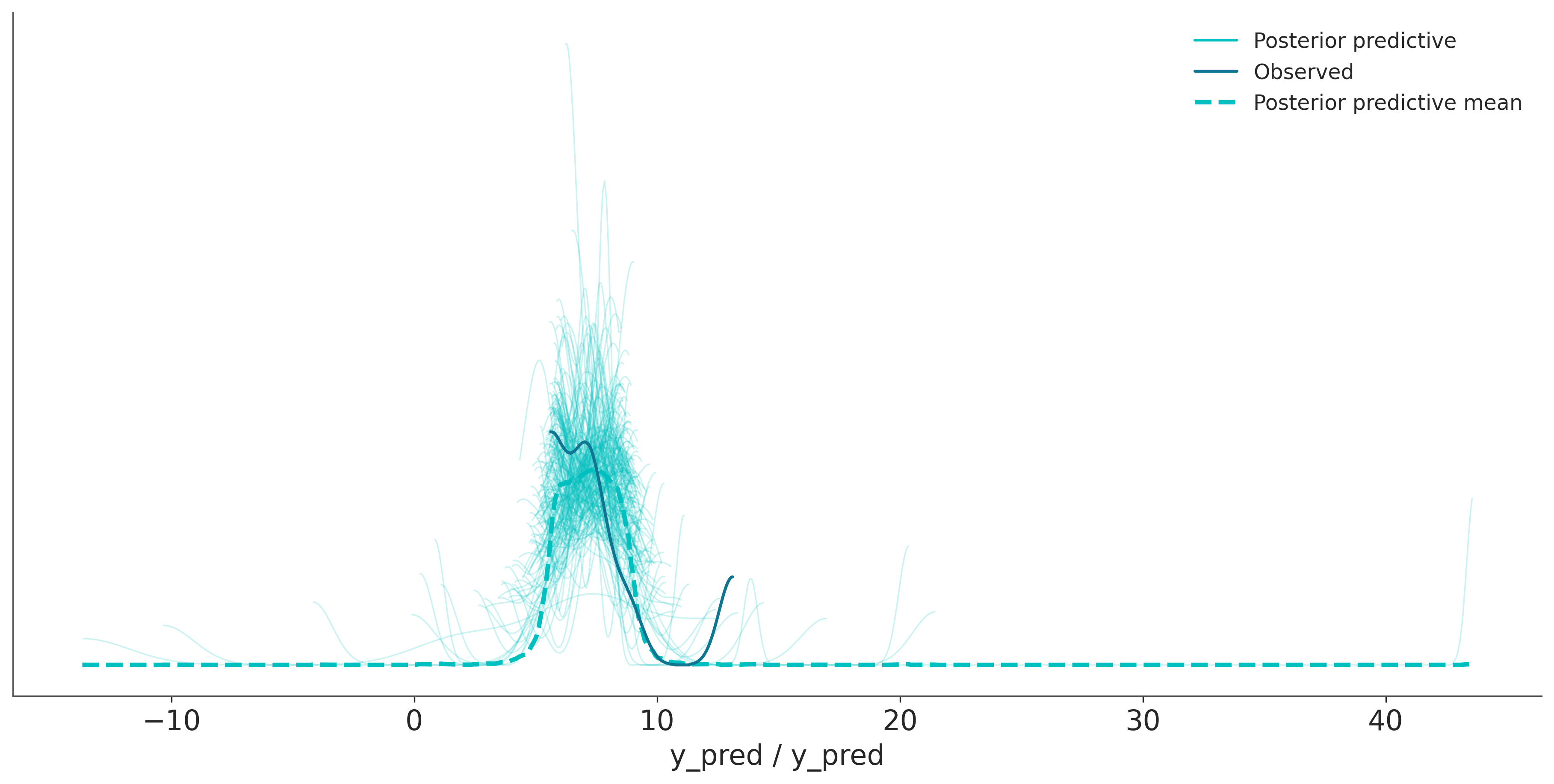
En la siguiente figura la línea azul es la media del número de bicicletas alquiladas, esto es lo mismo que ya vimos en la figura anterior. Los nuevos elementos son la banda turquesa oscuro, que representa el 50% central (cuartiles 0,25 y 0,5) para las bicicletas alquiladas y la banda turquesa claro, que representa el 94% central (cuartiles 0,03 y 0,97).
Podemos notar que nuestro modelo predice un número negativo de bicicletas, lo cual no tiene sentido para nuestro problema, ya que no estemas modelando robo o pérdida de bicicletas. Pero detengamonos un momento a reflexionar sobre nuestro modelo. Tiene sentido, según el modelo, que tengamos valores negativos de bicicletas?
Si, esto debería esperarse ya que usamos una distribución Normal como likelihood en modelo_bl. Una solución muy sucia podría ser recortar las predicciones para valores inferiores a cero, pero eso es feo, feo. En la siguiente sección, veremos que podemos mejorar fácilmente este modelo para evitar predicciones sin sentido.
El modelo lineal que hemos estado usando es un caso especial de un modelo más general, el modelo lineal generalizado (GLM, por su sigla en inglés). El GLM es una generalización del modelo lineal que nos permite utilizar diferentes distribuciones para el likelihood. De forma general (y omitiendo priors), podemos escribir un GLM como:
\[
\begin{aligned}
\mu &= \alpha + \beta X \\
Y &\sim \phi(f(\mu), \theta)
\end{aligned}
\]
donde \(\phi\) es una distribución arbitraria algunos casos comunes son Normal, Student’s T, Gamma, NegativeBinomial, pero podemos usar otras. \(\theta\) representa cualquier parámetro auxiliar o ruido que pueda tener la distribución, por ejemplo \(\sigma\) para la distribución Normal. También tenemos \(f\), generalmente llamada función de enlace inverso. Cuando \(\phi\) es Normal, entonces \(f\) es la función identidad. Para distribuciones como Gamma y NegativeBinomial, \(f\) suele ser la función exponencial. ¿Por qué necesitamos \(f\)? Porque \(\mu\) generalmente tomará valores en los reales, para una distribución como la Normal esto es correcto ya que la media está definida en los reales, pero esto no es necesariamente así para otras distribuciones. Por ejemplo, el parámetro \(\mu\) de la Negativa Binomial se define solo para números positivos, por lo que necesitamos una transformación que nos lleve de los reales a los positivos. La función exponencial es un buen candidato para esta transformación. Vamos a explorar varios GLM, un buen ejercicio es crear una tabla y cada vez que veamos una un nuevo GLM, agregar una línea que indique qué es \(\phi\), \(\theta\), \(f\) y tal vez algunas notas sobre cuándo se usa este GLM. Bien, comencemos con nuestro primer ejemplo concreto de un GLM.
6.4 Generalizando el modelo lineal para datos de conteo
¿Cómo podemos cambiar modelo_bl para acomodar mejor los datos de las bicicletas? Hay dos cosas a tener en cuenta, el número de bicicletas alquiladas es discreto y está acotado en cero. Esto generalmente se conoce como datos de conteo. Se les llama así porque son el resultado de contar algo. Los datos de conteo a veces se modelan usando una distribución continua como una Normal, especialmente cuando el número de conteos es grande. Pero a menudo es una buena idea usar una distribución discreta. Dos opciones comunes son la distribución de Poisson y el NegativaBinomial. La principal diferencia es que, para la distribución de Poisson, la media y la varianza son iguales y están controladas por un mismo parámetro. Asumir que la media y la varianza son idénticas puede no ser adecuado. En esos casos es común tomar como alternativa la distribución NegativaBinomial, ya que permite que la media y la varianza sean diferentes. Ante la duda es posible generar dos modelos y evaluar si una Poisson o una NegativaBinomial es más adecuada. Más adelante veremos algunos criterios para comparar modelos, por ahora vamos a usar la distribución NegativaBinomial.
El modelo de PyMC es muy similar al anterior, pero con dos diferencias principales. Primero, usamos pm.NegativeBinomial en lugar de pm.Normal para el likelihood. La distribución NegativaBinomial tiene dos parámetros, la media \(\mu\) y un parámetro de dispersión \(\alpha\). La varianza de la NegativaBinomial es \(\mu + \frac{\mu^2}{\alpha}\). Entonces, cuanto mayor sea el valor de \(\alpha\), mayor será la varianza. La segunda diferencia es que \(\mu\) es pm.math.exp(α + β * bikes.temperatura) en lugar de solo α + β * bikes.temperatura, como ya explicamos, esto es necesario para transformar los realaes a valores positivos.
La distribución predictiva a posteriori para modelo_neg se muestra en la siguiente figura. Podemos ver que ya no predecimos valores negativos y que la varianza de las predicciones aumenta con la media. Esto es de esperar ya que la varianza de la NegativaBinomial es \(\mu + \frac{\mu^2}{\alpha}\).
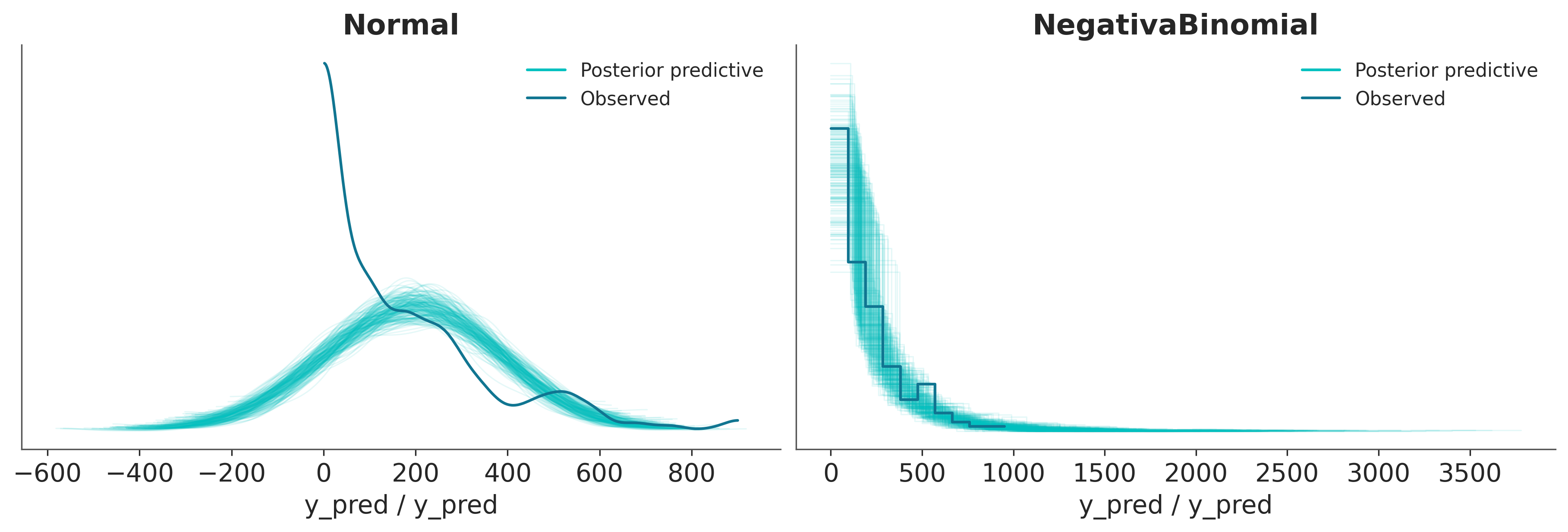
En la siguiente figura tenemos una prueba predictiva a posteriori para modelo_bl a la izquierda y modelo_neg a la derecha. Podemos ver que cuando se usa una Normal, la discrepancia más grande es que el modelo predice valores negativos para las bicicletas alquiladas, pero incluso para los valores positivos vemos que el el ajuste no es tan bueno. Por otro lado, el modelo con la distribución NegativaBinomial ajusta mejor los datos. Aunque el ajuste no es del todo perfecto, vemos que la cola de la distribución es más pesada para las predicciones que para las observaciones, pero también observamos que la probabilidad de esta demanda tan alta es baja. Entonces, en general, reafirmamos que el modelo NegativoBinomial es mejor que el Normal.
Una vez estaba ejecutando una simulación compleja de un sistema molecular. En cada paso de la simulación, necesitabamos calcular una regresión lineal como paso intermedio. Teníamos razones teóricas y empíricas para pensar que nuestra “Y” era condicionalmente normal dada nuestra “X”, por lo que la regresión lineal simple debía funcionar. Pero de vez en cuando la simulación generaba algunos valores de “Y” muy por encima o por debajo de la del grueso de los datos, esto arruinaba completamente nuestra simulación y tenáimos que reiniciarla. Estos valores muy diferentes al grueso de los datos se denominan valores atípicos o aberrantes. El motivo del fracaso de nuestras simulaciones era que los valores atípicos estaban tirando de la línea de regresión hacia valores que daban un muy mal ajuste para el grueso de los datos y cuando pasabamos de esta estimación al siguiente paso de la simulación, todo se detenía. Resolvimos esto con la ayuda de nuestra buena amiga, la distribución T de Student, que como vimos anteriormente, tiene colas más pesadas que la distribución Normal. Esto significa que los valores atípicos tienen menos influencia en el resultado final, que se asemeja más al resultado que hubieramos obtenido en ausencia de los valores atípicos. Esto es un ejemplo de una regresión robusta.
Para ejemplificar la robustez que la distribución T de Student aporta a la regresión lineal, vamos a utilizar un conjunto de datos muy simple. Una versión ligeramente modificada del tercer grupo de datos del cuarteto de Anscombe.
En el siguiente modelo, estamos usando una exponencial desplazada (le sumamos 1) para evitar valores cercanos a cero. La distribución exponencial (no desplazada) pone demasiado peso en los valores cercanos a cero. En mi experiencia, esto está bien para datos con valores atípicos “moderados”, pero en algunos conjuntos de datos pequeños como este, es mejor evitar valores tan bajos. Esta recomendación, como otras, hay que tomarlas con una pizca de sal. Los valores por defecto son buenos puntos de partida, pero no es necesario ceñirse a ellos. Otro priors comunes para Gamma(2, 0.1) o Gamma(mu = 20, sd = 15).
ans = pd.read_csv('datos/anscombe_3.csv')ans.plot("x", "y", kind="scatter");
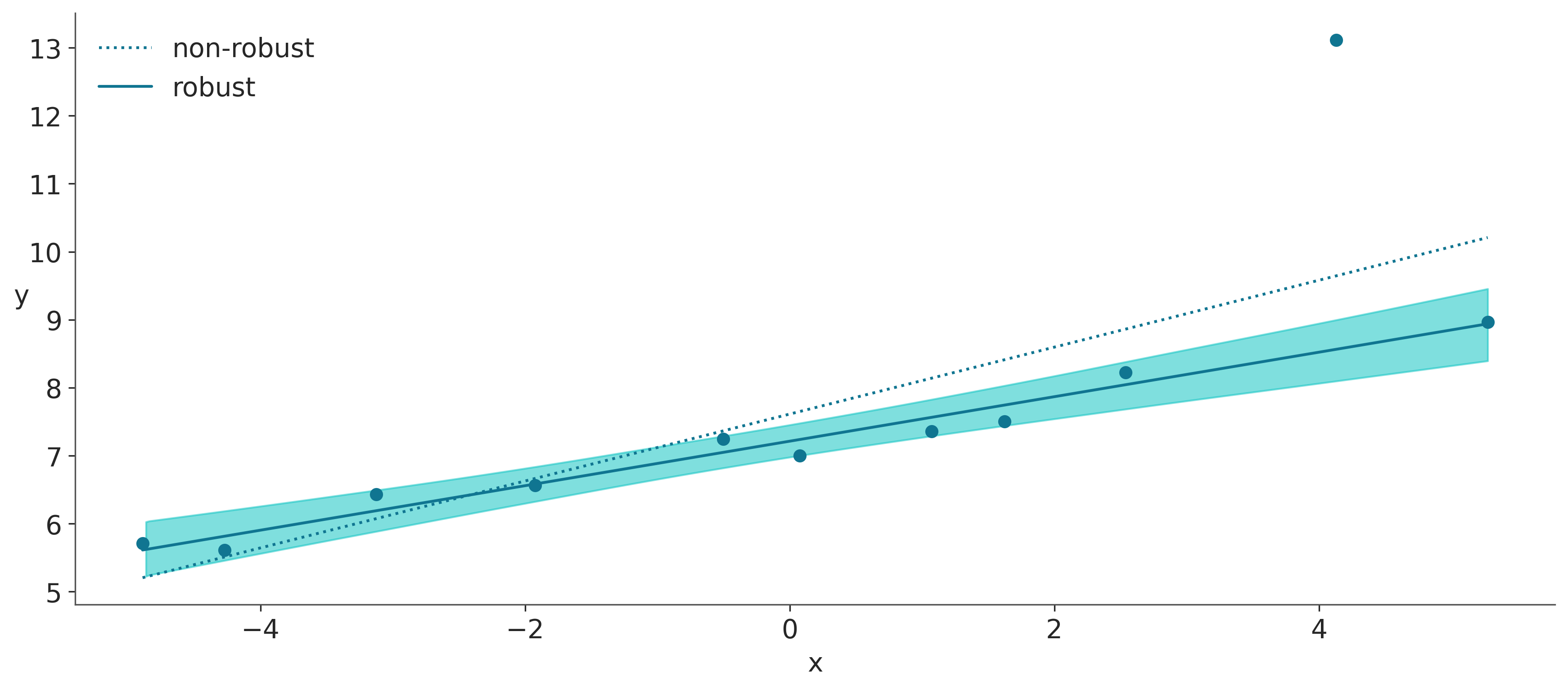
En la siguiente figura podemos ver el ajuste robusto, según model_t, y el ajuste no robusto, según linregress de SciPy (esta función está haciendo una regresión por mínimos cuadrados).
Mientras que el ajuste no robusto trata de comprometerse e incluir todos los puntos, el ajuste Bayesiano robusto, model_t, automáticamente descarta (o le reduce peso) a un punto y ajusta una línea que pasa más cerca de todos los puntos restantes
En la siguiente figura podemos ver que obtenemos una muy buena coincidencia. También podemos ver que nuestro modelo predice valores alejados del grueso de los datos hacia ambos lados.
La regresión logistica es la generalización del modelo de regresión simple para cuando la variable dependiente es binaria. Esta generalización se logra en dos pasos. Primero utilizamos la funcion logística como función inversa de enlace:
\[ \text{logística}(z) = \frac{1}{1 + e^{-z}} \]
Usamos esta función por que una de sus propiedades es que no importa el valor del argumento \(z\), el resultado siempre será un valor en el intervalo [0, 1]. La función logística es conocida también como función sigmoide, por su aspecto típico de S como se puede ver al ejecutar la siguiente celda:
z = np.linspace(-6, 6)logística =1/ (1+ np.exp(-z))plt.plot(z, logística)plt.xlabel('z')plt.ylabel('logística(z)');
El segundo paso consiste en usar como likelihood una distribución binomial y no una Gaussiana. De esta forma el modelo queda expresado como:
Esto modelo se puede explicar de la siguiente forma. Si nuestros datos son binarios \(y \in \{0, 1\}\), como con el ejemplo de la moneda, vemos que tiene sentido usar una distribución Bernoulli. Esta distribución está parametrizada por un único parámetro en el intervalo [0, 1], el cual puede ser generado desde un modelo lineal siempre y cuando los valores generados por el modelo lineal sean comprimidos al intervalo [0, 1], algo que puede ser obtenido al emplear una función logística.
6.7 El modelo logístico aplicado al conjunto de datos del iris.
Vamos a aplicar una regresión logística al conjunto de datos Iris. Este es un conjunto de datos clásico que contiene información sobre flores de 3 especies estrechamente relacionadas: setosa, virginica y versicolor. Estas serán nuestras variables dependientes, las clases que queremos predecir. Tenemos 50 individuos de cada especie y para cada individuo el conjunto de datos contiene cuatro variables que vamos a usar como variables independientes. Estas son el largo del pétalo, el ancho del pétalo, el largo del sépalo y el ancho del sépalo. Por si se lo están preguntando, los sépalos son hojas modificadas cuya función está generalmente relacionada con la protección de las flores en la yema.
iris = pd.read_csv('datos/iris.csv')iris.head()
sepal_length
sepal_width
petal_length
petal_width
species
0
5.1
3.5
1.4
0.2
setosa
1
4.9
3.0
1.4
0.2
setosa
2
4.7
3.2
1.3
0.2
setosa
3
4.6
3.1
1.5
0.2
setosa
4
5.0
3.6
1.4
0.2
setosa
Vamos a comenzar con la regresión logística más simple posible: dos clases, setosa y versicolor, y solo una variable independiente, la longitud del sépalo. Como se hace normalmente, vamos a codificar las variables categóricas setosa y versicolor con los números 0 y 1. Usando Pandas podemos hacer:
Al igual que con otros modelos lineales, centrar los datos puede ayudar con el muestreo. Ahora que tenemos los datos en el formato adecuado, finalmente podemos construir el modelo con PyMC.
Observe cómo la primera parte del siguiente modelo se asemeja a un modelo de regresión lineal. Este modelo tiene dos variables deterministas: θ ybd. θ es la salida de la función logística aplicada a la variable μ y bd es límite de decisión (el cual explicaremos más adelante). Otro punto que vale la pena mencionar es que en lugar de escribir explícitamente la función logística estamos usando pm.math.sigmoid.
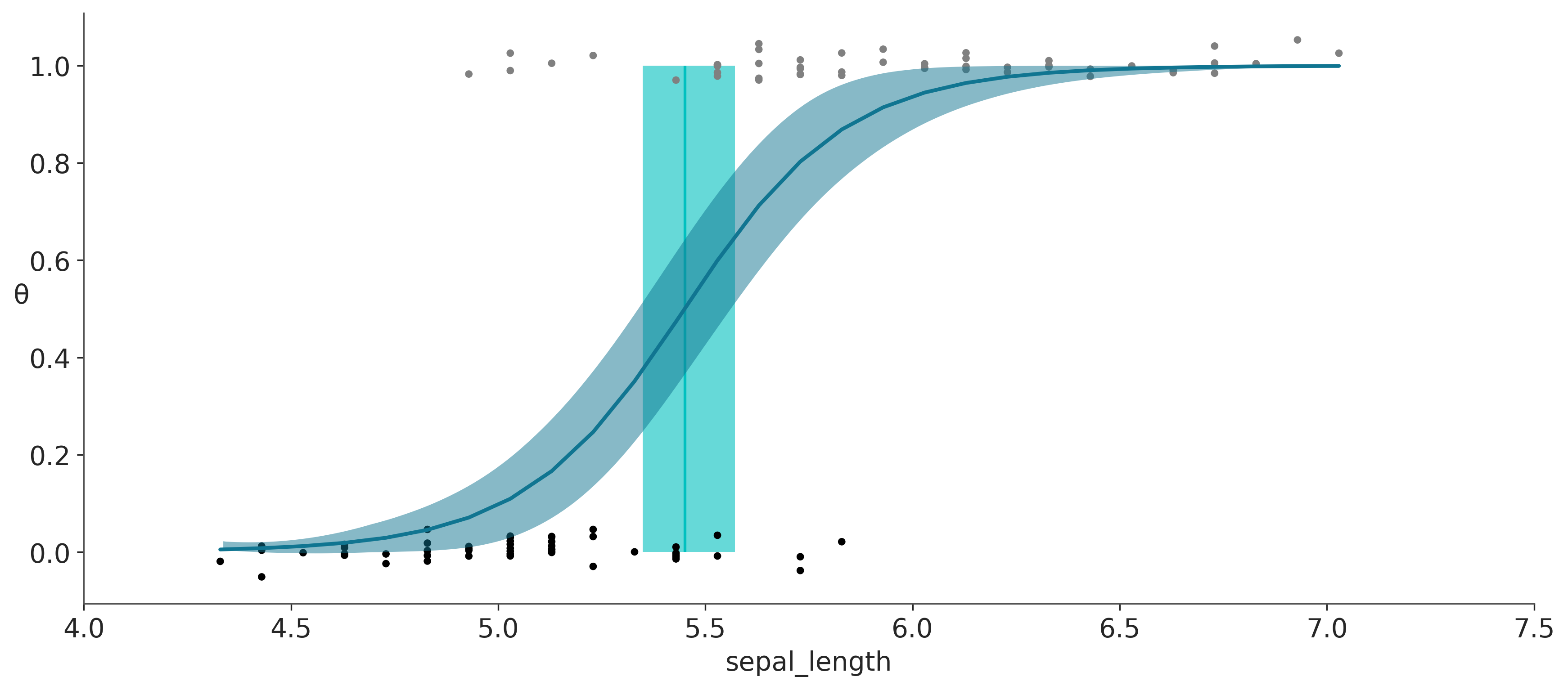
La figura anterior muestra la longitud del sépalo para las especies (setosa = 0, versicolor = 1). Para mitigar la superposición de los datos, hemos agregado ruido (jitter) a las variable-respuesta que es binaria. Una línea azul en forma de S representa el valor medio de \(\theta\). Esta línea se puede interpretar como la probabilidad que una flor sea versicolor dado el valor de longitud del sépalo. La banda azul semitransparente es el HDI 94%.
6.8 Clasificación con regresión logística
Mi madre prepara un plato delicioso llamado sopa seca, que básicamente es una receta a base de tallarines y que prácticamente no tienen agua. Si bien puede parecer un nombre inapropiado, el nombre del plato cobra total sentido cuando aprendemos cómo se cocina, una parte del agua que se agrega inicialmente se pierde por evaporación y la otra es absorvida por los fideos. Algo similar sucede con la regresión logística. Es usual que este modelo se muestre como un método de clasificación (y no de regresión). Veamos la fuente de esta dualidad.
Los problemas de regresión consisten en predecir un valor continuo para una variable de salida dados los valores de una o más variables de entrada. Y una clasificación es un problema de asignación de valores discretos a una variable de salida dadas unas variables de entrada. Por ejemplo, asignar la clases versicolor dada la longitud de su sépalo.
Entonces, ¿la regresión logística es una regresión o un método de clasificación? La respuesta es que es un método de regresión, solo que la regresión se hace sobre la probabilidad de pertenecer a una de dos clases. Pero también es posible usar una regresión logística como clasificador. Lo único que necesitamos es una regla de decisión. Por ej asignár la clase versicolor si \(\theta \ge 0.5\) y setosa en caso contrario.
La línea vertical en la figura anterior es el límite de decisión, y se define como el valor de la variable independiente que hace que la probabilidad de la clase 1 (versicolor en nuestro ejemplo) sea igual a 0,5. Para este modelo podemos calcular este valor analíticamente y es \(-\frac{\alpha}{\beta}\).
A partir de la definición del modelo tenemos la relación:
\[\theta = \text{logística}(\alpha + x \beta)\]
Y a partir de la definición de la función logística tenemos que \(\theta = 0.5\), cuando el argumento de la regresión logística es 0, es decir:
Reordenando encontramos que el valor de \(x_i\), para el cual, \(\theta = 0.5\) corresponde a la expresión:
\[x_i = - \frac{\alpha}{\beta}\]
Resumiendo los puntos más importantes hasta el momento:
El valor de \(\theta\) es, en términos generales, \(p(y= 1 \mid x)\). En este sentido, la regresión logística es en realidad una regresión, solo que estamos regresionando la probabilidad que una observación pertenezca a la clase 1.
Estamos modelando la media de una variable dicotómica, es decir, un número en el intervalo [0-1]. Luego, introducimos una regla para convertir esta probabilidad en una asignación de dos clases. En este caso, si \(p(y = 1) >= 0.5\) asignamos clase 1, de lo contrario clase 0.
No hay nada especial en el valor 0.5, aparte de que es el número en el medio entre 0 y 1. Podemos argumentar que este límite solo es razonable si estamos de acuerdo en cometer un error en una u otra dirección. En otras palabras, si es lo mismo para nosotros clasificar erróneamente una setosa como versicolor o una versicolor como setosa. Resulta que este no es siempre el caso, y el costo asociado a la clasificación errónea no tiene por qué ser simétrico.
6.9 Interpretación de los coeficientes de una regresión logística
Debemos tener cuidado al interpretar los coeficientes \(\beta\) de una regresión logística. La interpretación no es tan sencilla como con los modelos lineales en el capítulo anterior. La función logística introduce una no linearidad, que debemos tener en cuenta. Si \(\beta\) es positivo, aumentar \(x\) aumentará \(p(y = 1)\) en cierta cantidad, pero la cantidad no es una función lineal de \(x\), es en cambio una función no-lineal de \(x\). Podemos visualizar este hecho en la figura 4.4, en lugar de una línea con una pendiente constante, tenemos una línea en forma de S con una pendiente que cambia en función de \(x\). Un poco de álgebra nos puede dar una idea de cuánto cambia \(p(y=1)\) con \(\beta\):
El modelo logístico básico es:
\[\theta = logistic (\alpha + X \beta) \]
El inverso de la logística es la función logit, que es:
\[ logit(z) = log \left (\frac{z}{1-z} \right)\]
Por lo tanto, si tomamos la primera ecuación en esta sección y aplicamos la función logit a ambos términos, obtenemos:
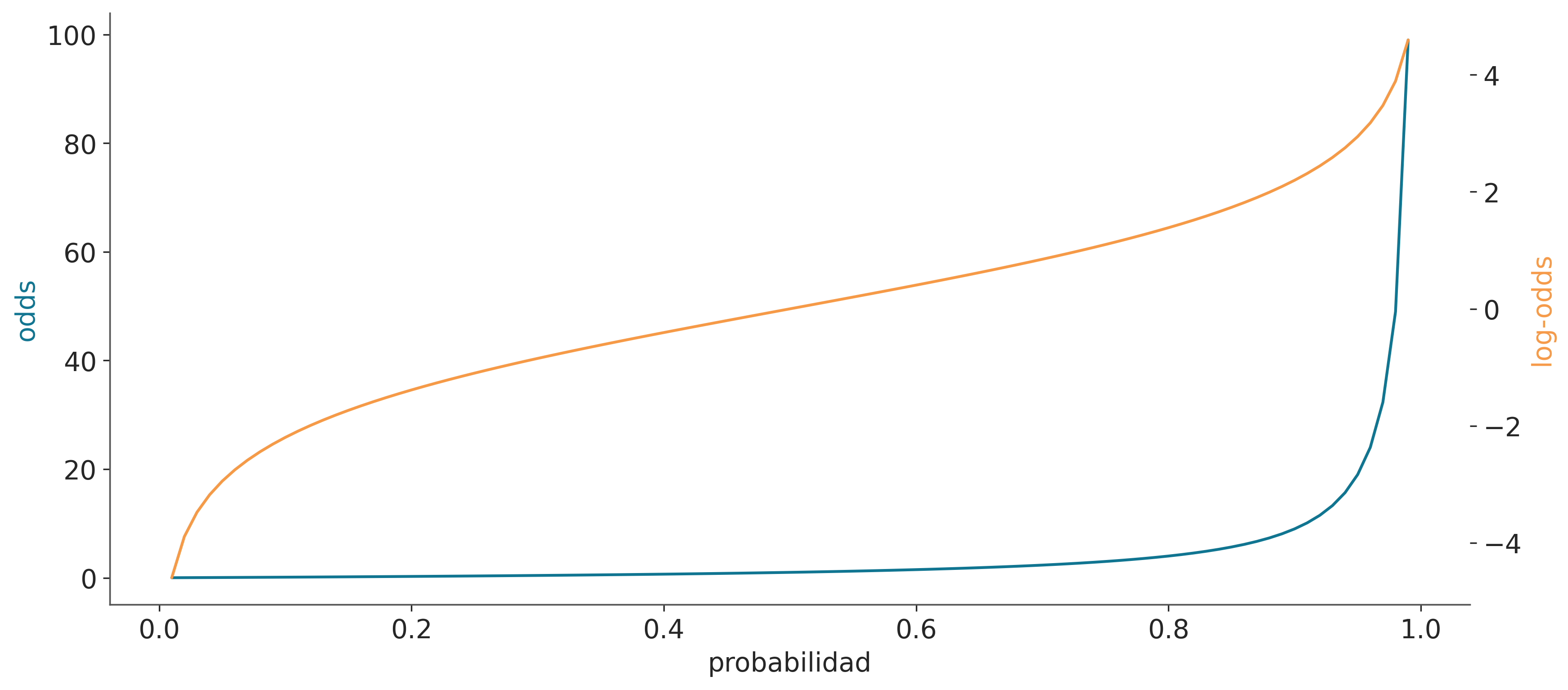
La cantidad \[\frac{p (y = 1)} {1-p (y = 1)}\] se conoce como odds. Los odds a favor se definen como la relación entre la probabilidad de éxito y la probabilidad de no éxito. Mientras que la probabilidad de obtener 2 tirando un dado es 1/6, los odds para el mismo evento son \(\frac{1/6}{5/6} = 0.2\) o dicho de otra forma 1 evento favorable frente a 5 eventos desfavorables. Mientras las probabilidades toman valores en el intervalo [0, 1], los odds lo hacen en \([0, \infty)\). Veamos otro ejemplo, si la probabilidad de lluvia mañana es \(\frac{3}{4}\), entonces la probabilidad de que no llueva es \(\frac{1}{4}\) y entonces el odds será de 3. Es decir es tres veces más probable que llueva respecto de que no llueva. Si en cambio la probabilidad fuese \(\frac{1}{2}\) entonces el odds sería 1. Es tan probable que llueva como que no lo haga. Los odds suelen ser utilizadas por los apostadores ya que proporcionan una herramienta más intuitiva que las probabilidades en bruto cuando se piensa en la forma correcta de apostar.
En una regresión logística, el coeficiente \(\beta\) codifica el aumento en unidades de log-odds por unidad de aumento de la variable \(x\).
La transformación de probabilidad a odds es una transformación monotónica, lo que significa que las probabilidades aumentan a medida que aumenta la probabilidad. Mientras que las probabilidades están restringidas al intervalo \([0, 1]\), los odds viven en el intervalo \([0, \infty]\). El logaritmo es otra transformación monótonica y los log-odds están en el intervalo \([-\infty, \infty]\). La siguiente figura muestra cómo la probabilidad está relacionada con los odds y los log-odds.
/tmp/ipykernel_50519/2677285095.py:2: RuntimeWarning: divide by zero encountered in divide
odds = probability / (1 - probability)
Entonces averigüemos cuantas veces más probable es que una flor sea versicolor por unidad del largo del sépalo
6.10 Varianza variable
Hemos estado usando el modelo lineal para modelar la media de una distribución, dejando la varianza de lado. En caso que consideremos que el supuesto de varianza constante no tiene sentido podemos considerar la varianza como una función (lineal) de la variable dependiente.
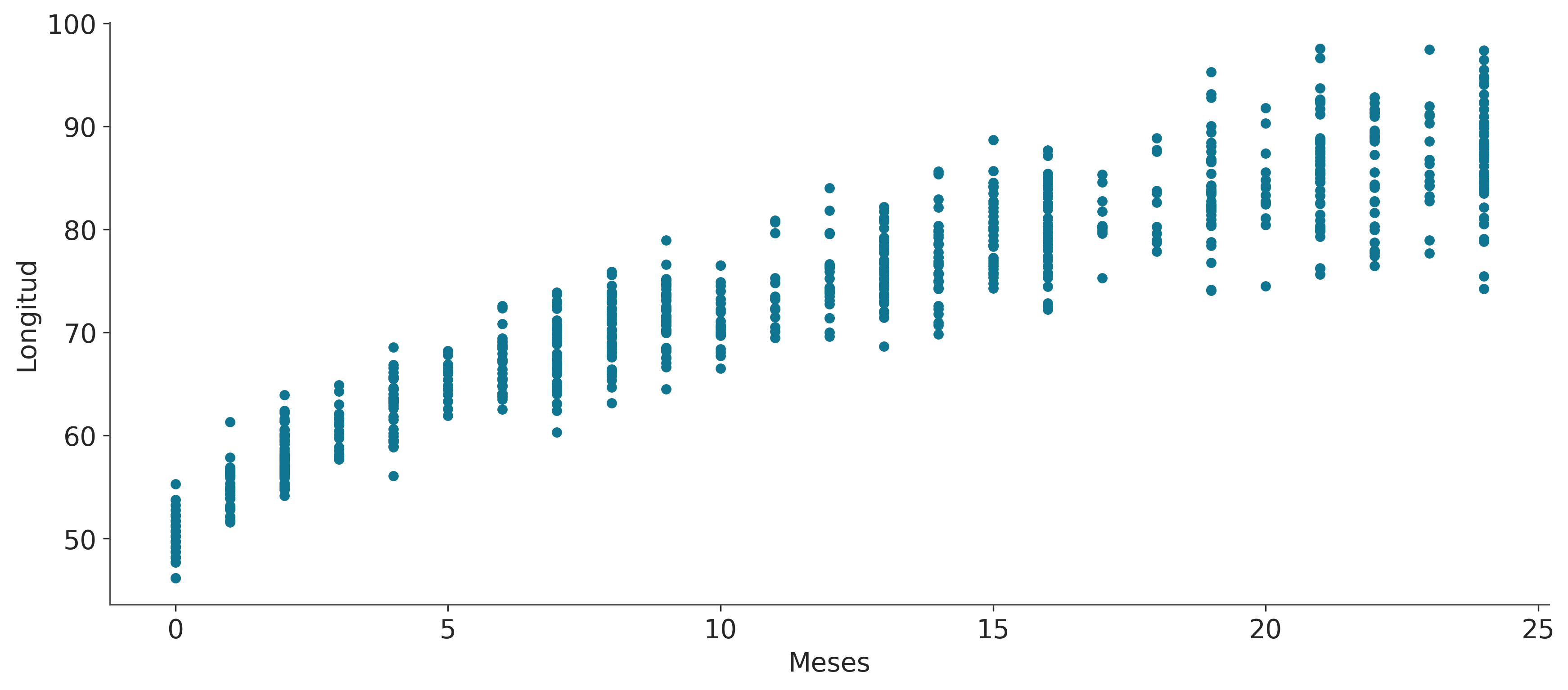
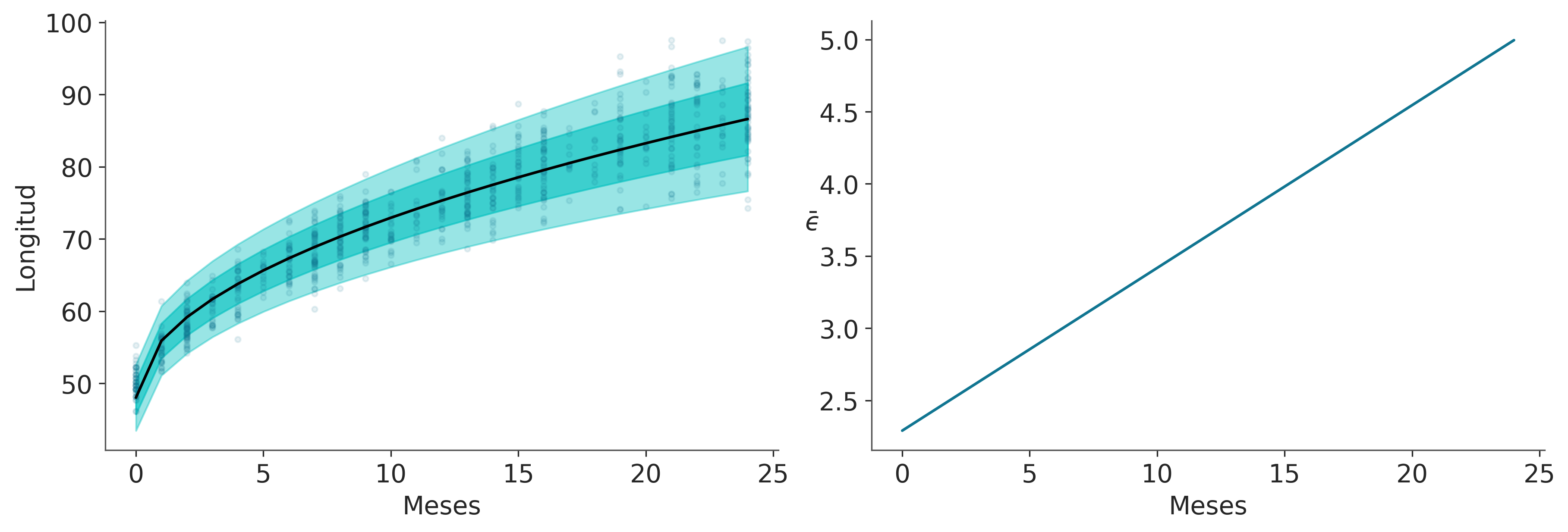
La Organización Mundial de la Salud y otras instituciones de salud de todo el mundo recopilan datos para recién nacidos y diseñan estándares de crecimiento. Estas tablas son un componente esencial del conjunto de herramientas pediátricas y también como una medida del bienestar general de las poblaciones con el fin de formular políticas de salud, planificar intervenciones y controlar su eficacia. Un ejemplo de tales datos son la longitud (alturas) de las niñas recién nacidas en función de la edad (en meses):
data = pd.read_csv('datos/babies.csv')data.plot.scatter('Meses', 'Longitud');
Para modelar estos datos, presentaremos 3 elementos nuevos en comparación con los modelos anteriores:
\(\sigma\) ahora es una función lineal de \(x\), y para hacer esto agregamos dos nuevos parámetros \(\gamma\) y \(\delta\), estos son análogos directos de \(\alpha\) y \(\beta\).
El modelo lineal para la media es una función de \(\sqrt{x}\), esto es solo un truco simple para ajustar un modelo lineal a una curva.
Hemos definido una variable compartida x_shared, esto nos permitirá cambiar los valores de la variable \(x\) (Meses en este ejemplo) sin la necesidad de volver a muestrear el modelo. Esto quedará más claro con el ejemplo.
La siguiente figura muestra el resultado de nuestro modelo. La media de \(\mu\) es representada con una curva negra, y las dos bandas turquesa semitransparentes representan 1 y 2 desviaciones estándar.
Ahora que tenemos ajustado el modelo podríamos querer usar el modelo para averiguar cómo se compara la longitud de una niña en particular respecto de la distribución. Una forma de responder a esta pregunta es preguntarle al modelo por la distribución de la variable longitud para bebas de digamos de 0.5 meses. Usando PyMC podemos hacer estas preguntas con la función pm.sample_posterior_predictive, ya que esto arrojará muestras de \(\tilde y\) es decir los valores predichos considerando la incertidumbre de los parámetros. El único problema es que, por defecto, esta función devolverá valores de \(\tilde y\) para los valores observados de \(x\), es decir los valores usando para ajustar el modelo. Pero que pasa si queremos obtener predicciones para que el modelo no vio? Como 0,5 meses que no es parte de los datos originales. La manera más fácil de obtener predicciones para valores no observados es definir una variable compartida (x_shared en el ejemplo) y luego actualizar el valor de la variable compartida justo antes del muestreo de la distribución predictiva a posteriori.
Ahora podemos graficar la distribución esperada de las longitudes para las bebas con 2 semanas de vida y calcular cantidades adicionales, por ejemplo, el percentil de una niña de esa longitud:
En los ejemplos anteriores nos focalizamos en usar un modelo lineal para estimar la media de la variable respuesta, también vimos que es posible usar la misma idea para estimar la varianza. Además, aprendimos que usar un likelihood Normal es solo una de muchas opciones, como Binomial, Negativa Binomial, t de Student, etc.
En esta sección vamos a discutir un modelo lineal, cuyo objetivo no es la estimación de media o varianza, en cambio la estimación de cuantiles. Cuando el cuantil a estimar es la mediana, la motivación suele ser la necesidad de una regresión robusta. Así como la mediana es un estimador de la media, robusto a valores extremos, una regresión mediana será también robusta. En ese caso la regresión por cuantiles cumpliría una función similar al modelo robusto que vimos anteriormente usando una distribución t de Student. Otras veces, la motivación está en modelar cuantiles específicos por que estos son “intrínsecamente” de interés. Esto sucede por ejemplo cuando nos interesa modelador valores en los extremos de una distribución. Por ejemplo podríamos estar interesados en modelar temperaturas altas, o eventos de lluvia intensos. A veces también se usa para explorar relaciones entre variables cuando no hay relación entre las medias de dichas variables, o cuando esta es muy débil. Una disciplina donde las regresiones por cuantiles son frecuentes es la ecología. Esto se debe posiblemente, a que la existencia de complejas interacciones entre variables, donde el efecto de una variable sobre otra es distinto para distintos rangos de la variable.
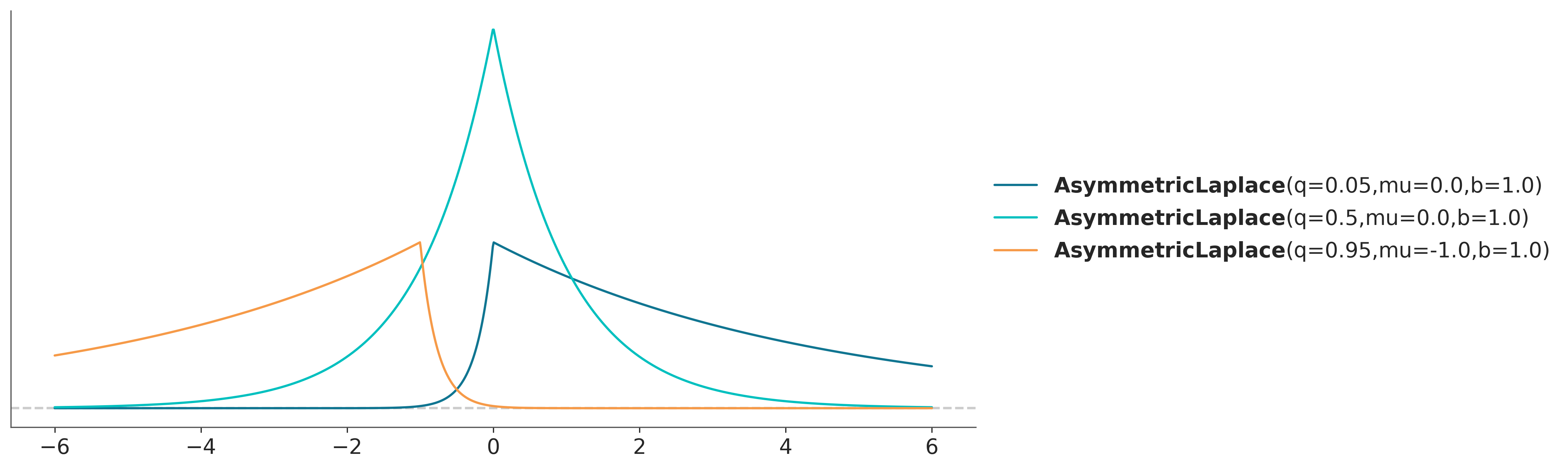
Para hacer regresiones por cuantiles utilizamos la distribución asimétrica de Laplace como likelihood. Esta distribución la podemos pensar como dos distribuciones exponenciales espalda-con-espalda. La distribución tiene 3 parámetros \(\mu\) controla la localización, \(\sigma\) la escala y \(q\) la asimetría. \(q\) varía entre [0, 1], cuando \(q=0.5\) la distribución asimétrica de Laplace es en realidad simétrica. Este caso especial es conocido también como distribución de Laplace. Cuando hacemos regresión por cuantiles, podemos pensar a \(q\) como los cuantiles que nos interesa asociar con la variable respuesta. Por ejemplo, si \(q=0.5\) estamos modelando la mediana, si \(q=0.25\) estamos modelando el primer cuartil, etc.
La siguiente figuras muestras tres distribuciones de esta familia.
Quiere decir esto que al hacer una regresión por cuantiles estamos asumiendo que la variable respuesta se distribuye (condicionalmente) como una Asimétrica de Laplace? No necesariamente.
Una forma alternativa de pensar el likelihood, es como una función de error (o de diferencia) entre el ajuste lineal y los datos. Al elegir una distribución determinada estamos, indirectamente, eligiendo como penalizaremos esa diferencia y al hacer inferencia estámos encontrando la distribución de parámetros que reducen esa diferencia. Usando esta lógica podemos pensar que una gaussiana le asigna un determinado peso a valores alejados de la media y una t de Student le asigna un menor peso, y por ende terminamos teniendo un ajuste más robusto. De la misma forma una asimétrica de Laplace le asigna una determinado peso a estas diferencias de forma tal que el resultado final es ajustar cuantiles en vez de medias. Si esto les suena extraño es por que están prestando atención.
Para ejemplificar la regresión por cuantiles vamos a usar el dataset de las longitudes de bebés que usamos anteriormente. Vamos a ajustar 3 cuantiles al mismo tiempo, 0.05, 0.5, 0.95. Esto nos va a permitir ver como cambia la relación entre las variables a medida que nos movemos de los cuantiles bajos a los altos. Para esto vamos a “apilar” el dataset 3 veces, una para cada cuantil.
Podemos ver que al usar una distribución Normal y a partir de ella computar los cuantiles, q=0.1 (\(\mu - 1.65\sigma\)) y q=0.9 (\(\mu + 1.65\sigma\)) estos son simétricos respecto de la media \(\mu\). Además podemos ver que la forma de la curva es esencialmente la misma para los 3 casos, solo que desplazada hacia arriba o abajo. Además las curvas generadas al usar la distribución asimétrica de Laplace permite acomodarse a la varianza no constante, vean como las curvas empiezan muy cerca en el mes cero y se van separando a medida que pasan los meses.
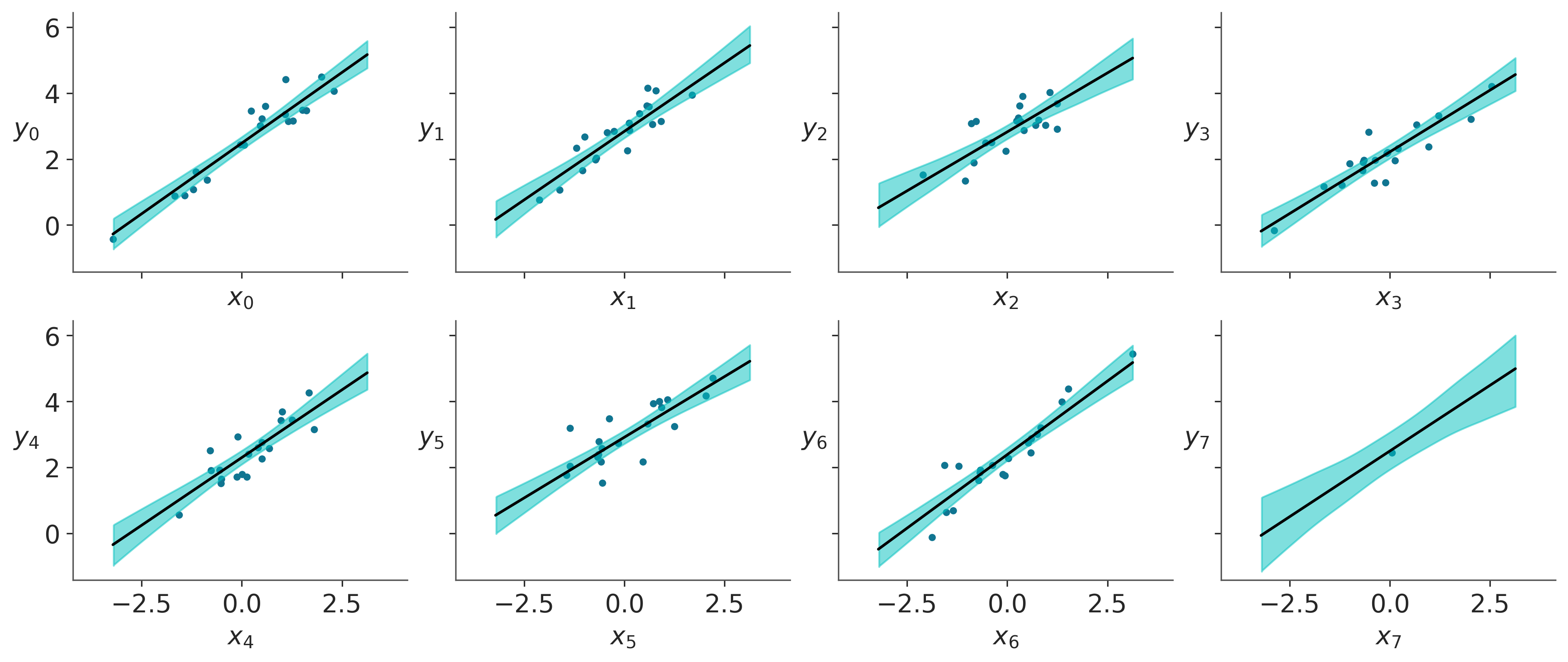
6.12 Regresión lineal jerárquica
Hace dos capítulos, aprendimos los rudimentos de los modelos jerárquicos. Este mismo concepto se puede aplicar a las regresiones lineales. Esto permite que los modelos realicen inferencias a nivel de subgrupo y a nivel global. Como ya vimos, esto se hace incluyendo hiperpriors.
Vamos a crear ocho grupos de datos relacionados, incluido un grupo con un solo dato
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [α_μ, α_σ, β_μ, β_σ, α, β, σ]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 5 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
There were 149 divergences after tuning. Increase `target_accept` or reparameterize.
Vemos que obtenemos un mesaje de advertencia indicando divergencias y dos sugerencias para solucionar el problema. La primera es incrementar target_accept la segunda reparametrizar. Este mensaje indica que las muestras generadas por PyMC pueden no ser confiables, esto se vincula a los diagnósticos que vimos en el capítulo anterior.
La primer sugerencias es aumentar target_accept, que es un argumento de pm.sample() que por defecto toma el valor 0.8 y puede tomar valores en el intervalo (0, 1). Si ves divergencias, como en este caso, cambiar el valor por defecto a valores tales como 0.85, 0.9 o incluso más puede ayudar. En algunos casos incluso valores altos como 0.99 no serán de ayuda. Un efecto adverso de aumentar target_accept es que el sampler suele demorar más en generar una misma cantidad de muestras.
Si las divergencias no desaparecen al cambiar target_accept, en general la única solución es reparametrizar. ¿Qué es esto? Reparametrizar es escribir un modelo de una manera diferente, pero matemáticamente equivalente a su versión original. Muchos modelos (por no decir todos) se pueden escribir de formas alternativas. A veces, la reparametrización puede tener un efecto positivo en la eficiencia del método de muestreo o en la interpretabilidad del modelo. Por ejemplo, al reparametrizar podemos eliminar las divergencias.
Si prueban volver a correr modelo_jerárquico pero con valores más altos de target_accept verán que las divergecias disminuyen pero no desaparecen. Lamentablemente esto es algo común con modelos lineales jerárquicos, lo bueno es que existe una reparametrización que suele solucionar el problema. La reparametrización consiste en reescribir el modelo de la siguiente forma:
En vez definir \(\beta \mathcal{N}(\beta_\mu, \beta_\sigma)\) como en modelo_jerárquico vamos a escribir \(\beta = \beta_\mu + \beta_\text{offset} * \beta_\sigma\). Donde \(\beta_\text{offset}\) es una distribución normal con media 0 y desviación estándar 1. Conceptualmente la diferencia es que en el primer caso estamos modelando la pendiente de cada grupo de forma explícita, mientras que en el segundo caso lo estamos haciendo como una desviación respecto de un valor común (\(\beta_\mu\)). A la primer versión se la suele llamar centrada y a la segunda no-centrada. Veamos como queda el modelo no-centrado en PyMC:
Al correr jerárquico_no_centrado sin modificar target_accept verán todavía quedan unas pocas divergencias. 2 en mi caso, un número tan bajo no suele ser problemático. Pero para estar seguros podemos aumentar target_accept a 0.85, como en el bloque de código anterior. Al hacer eso veremos que no hay divergencias y podremos seguir con nuestro análisis. Pero antes de hacer eso veamos que es lo que estamos haciendo al reparametrizar.
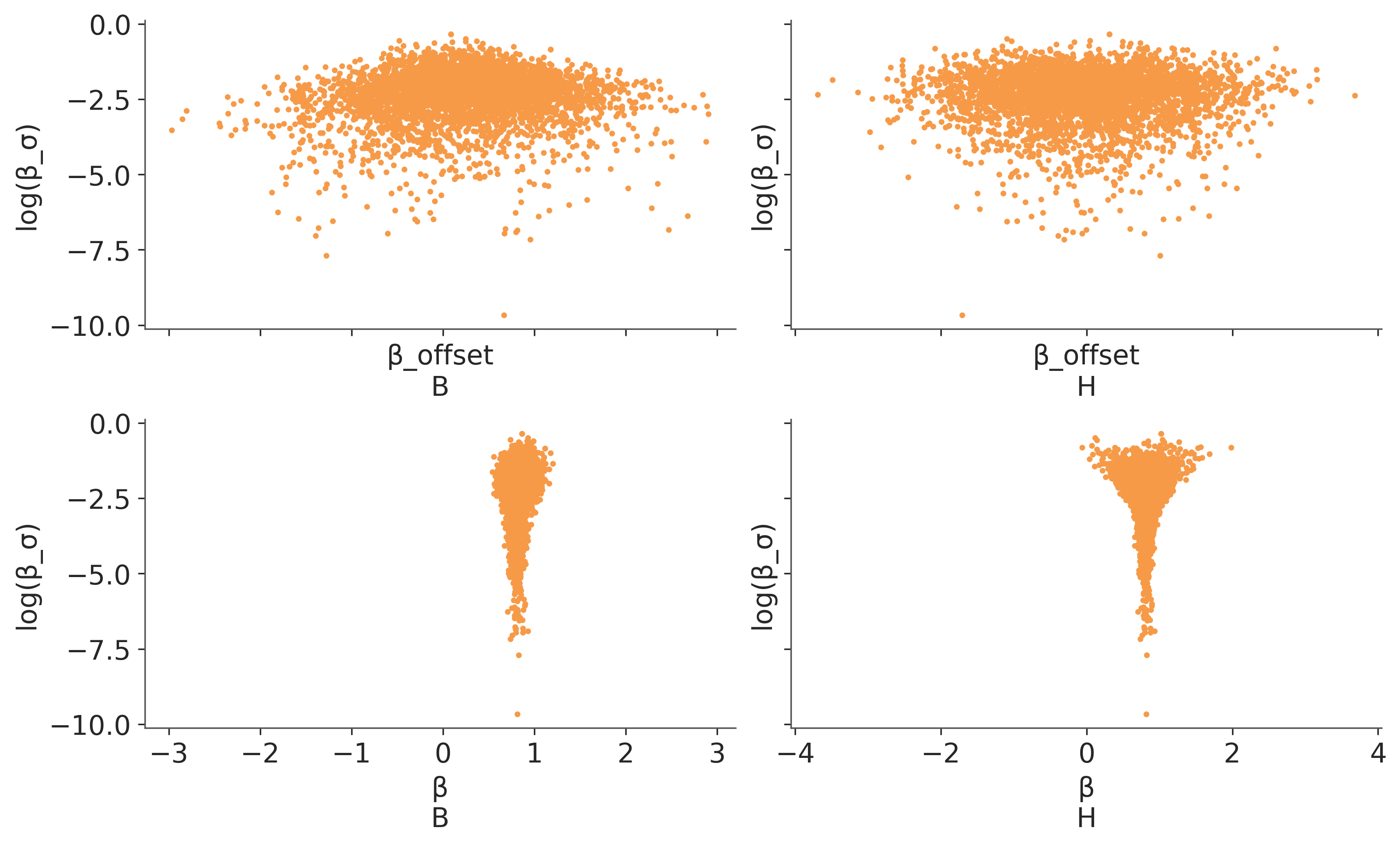
La siguiente figura muestra muestra dos paneles, a la izquierda tenemos un gráfico de dispersión entre los valores de \(\log \beta_\sigma\) (el logaritmo de la desviación estándar global) y \(\beta_B\). A la derecha entre \(\log \beta_\sigma\) y la pendiente del grupo H. Los puntos negros representan divergencias. En ambos casos se observa una forma de “embudo” más ancha arriba y más angosta abajo (esto es más acentuado en el panel de la derecha). En ambos casos a medida que \(\beta_\sigma\) aumenta el embudo se ensancha, ya que la dispersión de \(\beta\) aumenta. Esto es razonable ya que precisamente \(\beta_\sigma\) controla cuan variable puede ser \(\beta\) respecto de su media. En si mismo esto no es un problema, es simplemente una consecuencia directa del modelo. Pero si es un problema para el método de muestreo, como vimos en el capítulo anterior, para obtener un método eficiente el método de muestreo debe “aprender” ciertos hiper-parámetros. El problema que en una geometría como el embudo, no hay un solo conjunto de hiper-parámetros que sean lo suficientemente buenos para muestrear tanto la boca del embudo como su pico. En general el método “aprende” a muestrear la parate ancha y cuando se aproxima a la parte angosta la trayectoria “diverge” de la correcta. Es como si usáramos los cálculos para poner un satélite en orbita de la tierra, para ponerlo en órbita de la luna, perderíamos el satélite en el espacio.
Nota: Para la figura usamos \(\log \beta_\sigma\) en vez de \(\beta_\sigma\), por que esto es lo que “ve” el sampler. Por qué? Por que internamente PyMC muestrea los parámetros en un espacio sin “bordes” para eso convierte distribuciones como la Beta que tienen soporte en el intervalo (0, 1) a una distribución que tiene soporte en todo el espacio real. Lo mismo hace con distribuciones como la media-normal. En el caso de esta última la transformación es logarítmica. Una vez terminado el muestreo PyMC invierte la trasformación quedando los parámetros en la escala original y por eso nosotros vemos los valores de \(\beta_\sigma\) y no \(\log \beta_\sigma\). Pero el sampler ve \(\log \beta_\sigma\) por eso es conveniente graficar en esa escala.
Ahora bien, que pasa cuando usamos un modelo jerárquico no centrado? Veamos la siguiente figura:
Ahora tenemos 4 paneles, en la primer fila vemos \(\log \beta_\sigma\) vs \(\log \beta_{text{offset}}\), que es la nueva variable que introdujimos en la versión no centrada. Ahora vemos que el posterior es más “esférico” o al menos que la forma de embudo es mucho menos pronunciada. Esta geométrica es mucho más simple de muestrear que la anterior y por eso no observamos divergencias.
En la segunda fila vemos \(\log \beta_\sigma\) vs \(\beta\), ahora vemos que el embudo es aún más acentuado que en la figura anterior. Esto no debería ser aún más problemático? En realidad no, esto no es un problema para el sampler por que el sampler nunca “ve” este embudo ya que \(\beta\) lo obtenemos al combinar \(\beta_\text{offset}\), \(\beta_\sigma\) y \(\beta_\mu\). Es decir con la reparametrización logramos obtener un embudo más “profundo”, pero sin muestrearlo directamente!
Ahora que quiere decir que ahora el embudo sea “más profundo”? Quiere decir que ahora somos capaces de muestrear una región de la distribución a posteriori que antes no podíamos. En la versión centrada del modelo el sampler divergía antes de poder encontrar la zona angosta y por lo tanto esa zona NO estaba presente en la distribución a posteriori. Nos estábamos perdiendo parte de la distribución a posteriori, que si no fuera por las divergencias no sabríamos que existe y estaríamos trabajando con una distribución a posteriori sesgada sin siquiera saberlo.
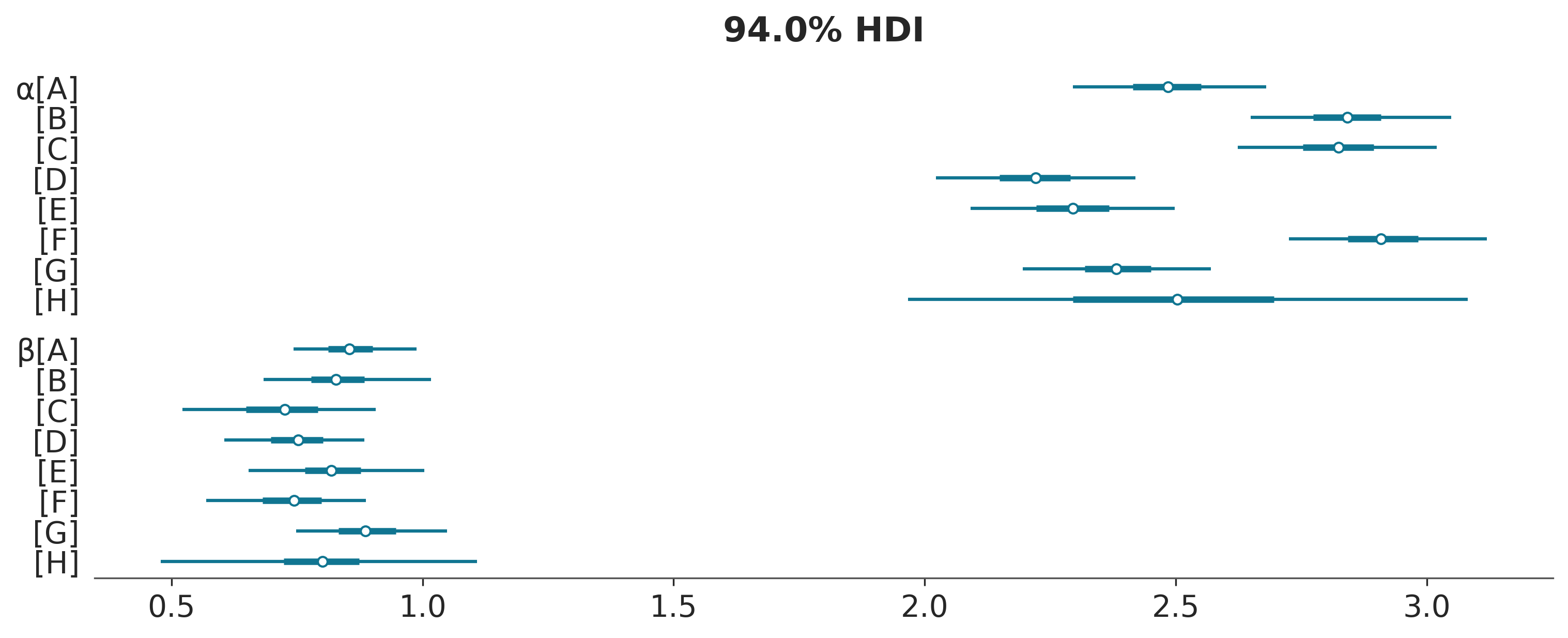
Ahora que nuestras muestras están libres de divergencias, podemos continuar con el análisis de los resultados. La siguiente figura muestra los valores estimados para \(\alpha\) y \(\beta\). Podemos ver como las estimaciones para el grupo H son las de mayor incertidumbre. Lo cual es razonable dado que tenemos un solo punto.
La siguiente figura muestra las líneas ajustadas para cada uno de los ocho grupos. Podemos ver que logramos ajustar una línea a un solo punto. Al principio, esto puede sonar extraño o incluso sospechoso, pero es solo una consecuencia de la estructura del modelo jerárquico. Cada línea está informada por las líneas de los otros grupos, por lo que no estamos realmente ajustando una línea a un solo punto. En cambio, estamos ajustando una línea que ha sido informada por los puntos en los otros grupos a un solo punto.
Hasta ahora, hemos estado trabajando con una variable dependiente y una variable independiente. Sin embargo, no es inusual tener varias variables independientes que queremos incluir en nuestro modelo. Algunos ejemplos podrían ser:
Calidad percibida del vino (dependiente) y acidez, densidad, grado alcohólico, azúcar residual y contenido de sulfatos (variables independientes)
Calificaciones promedio de un estudiante (dependiente) e ingreso familiar, distancia del hogar a la escuela y nivel de educación de la madre (variable categórica)
Podemos extender fácilmente el modelo de regresión lineal simple para tratar con más de una variable independiente. Llamamos a este modelo regresión lineal múltiple o menos a menudo regresión lineal multivariable (que no debe confundirse con la regresión lineal multivariable, el caso en el que tenemos múltiples variables dependientes).
En un modelo de regresión lineal múltiple, modelamos la media de la variable dependiente de la siguiente manera:
Usando notación de álgebra lineal, podemos escribir una versión más corta:
\[
\mu = \alpha + \mathbf{X} \beta
\]
donde \(\mathbf{X}\) es una matriz de tamaño \(n \times k\) con los valores de las variables independientes y \(\beta\) es un vector de tamaño \(k\) con los coeficientes de las variables independientes, y $n $ es el número de observaciones.
Si estás un poco oxidado con respecto al álgebra lineal, podés consultar el artículo de Wikipedia sobre el producto escalar entre dos vectores y su generalización a la multiplicación de matrices. Pero básicamente, lo que necesitás saber es que solo estamos usando una forma más corta y conveniente de escribir nuestro modelo:
Usando el modelo de regresión lineal simple, encontramos una línea recta que (con suerte) explica nuestros datos. Bajo el modelo de regresión lineal múltiple encontramos, en cambio, un hiperplano de dimensión \(k\). Por lo tanto, el modelo de regresión lineal múltiple es esencialmente el mismo que el modelo de regresión lineal simple, con la única diferencia de que ahora \(\beta\) es un vector y \(\mathbf{X}\) es una matriz.
Para ver un ejemplo de un modelo de regresión lineal múltiple, volvamos al ejemplo de las bicicletas. Usaremos la temperatura y la humedad del día para predecir el número de bicicletas alquiladas.
Tomemos un momento para comparar model_mlb que tiene dos variables independientes temperatura y hora con model_neg que solo tiene una variable independiente temperatura. La única diferencia es que ahora tenemos dos coeficientes \(\beta\), uno para cada variable independiente. El resto del modelo es el mismo. Podríamos haber escrito β = pm.Normal("β1", mu=0, sigma=10, shape=2) y luego usar β1[0] y β1[1] en la definición de \(\mu\). Yo suelo hacer eso, pero acá por ser el primer modelo de regresión múltiple, me pareció más claro escribirlo de esta manera.
Podemos ver que escribir un modelo de regresión múltiple no es tan diferente de escribir un modelo de regresión simple. Sin embargo, interpretar los resultados puede ser más desafiante. Por ejemplo, el coeficiente de temperatura ahora es \(\beta_0\) y el coeficiente de hora es \(\beta_1\). Todavía podemos interpretar los coeficientes como el cambio en la variable dependiente por cambio unitario en la variable independiente. Pero ahora debemos tener cuidado de especificar de qué variable independiente estamos hablando. Por ejemplo, podemos decir que por una unidad de aumento en la temperatura, el número de bicicletas alquiladas aumenta en \(\beta_0\) unidades, manteniendo constante la hora. O podemos decir que por una unidad de aumento en la hora, el número de bicicletas alquiladas aumenta en \(\beta_1\) unidades, manteniendo la temperatura constante. Pero tenemos que entender que dado que las variables participan todas del mismo modelo, no podemos hablar de sus coeficientes de forma aislada. Esto lo podemos ver en la siguiente figura, que muestra los coeficientes \(\beta\) para los modelos model_neg (solo temperatura) y para el modelo model_mld (temperatura y hora).
# Para hacer comparables los coeficientes los escalamos respecto de su correspondiente desviación estándaridata_neg.posterior["β0_scaled"] = idata_neg.posterior["β"] * bicis.temperatura.std()idata_mlb.posterior["β0_scaled"] = idata_mlb.posterior["β0"] * bicis.temperatura.std()idata_mlb.posterior["β1_scaled"] = idata_mlb.posterior["β1"] * bicis.hora.std()az.plot_forest([idata_neg, idata_mlb], model_names=["model_neg", "model_mlb"], var_names=["β0_scaled", "β1_scaled"], figsize=(10, 3), combined=True)
En la figura anterior podemos ver que el coeficiente \(\beta_0\), que se corresponde con la temperatura es diferente en ambos modelos. Esto se debe a que el efecto de la hora ya explica algunas de las variaciones en el número de bicicletas alquiladas que anteriormente solo se explicaban por la temperatura. En casos extremos, la adición de una nueva variable puede llevar el coeficiente a cero o incluso cambiar el signo. Hablaremos más de esto en el próximo capítulo.
6.14 Ejercicios
En la siguiente definición de modelo probabilístico cual es el likelihood, cual es el a priori y cual el a posteriori.
Usando el conjunto de datos howell (disponible junto con esta notebook) realice un modelo lineal del peso (\(x\)) versus la altura (\(y\)). Excluya a los menores de 18 años. Exponga los resultados.
Para 4 individuos se registraron los pesos (45.73, 65.8, 54.2, 32.59), pero no las alturas. Usando el modelo del punto anterior prediga la altura esperada para cada individuo junto con un intervalo de credibilidad del 50% y del 89%.
Repita el punto 4 pero para los menores de 18 años. Exponga los resultados.
Use el modelo modelo_bl pero aplicada al conjunto de datos iris. Intente clasificar setosa o versicolor en función de sepal_length. ¿Cuán útil es este modelo comparado con una regresión logística?
Vuelva a correr el modelo_rl pero esta vez usando la variable petal_width ¿En que difieren los resultados? ¿Cuán ancho o angosto es el intervalo HDI 94%?
Lea este post y replique los resultados usted mismo.