1 Probabilidad
La teoría de la probabilidad es tan solo sentido común reducido a cálculo. -Pierre-Simon Laplace
Los objetivos de este capítulo son:
- Brindar una introducción (o repaso) de nociones de algunos términos y conceptos generales de estadística
- Introducir la librería de Python PreliZ
1.1 Azahar, azar y dados
Las palabras azahar y azar no son similares por casualidad ambas provienen de la misma palabra árabe que significa flor. Desde la antigüedad, y hasta el día de hoy, ciertos juegos, como el juego de la taba, utilizan un hueso con dos lados planos a modo de dado. De hecho se podría decir que la taba es el antecesor del dado moderno. Para facilitar distinguir un lado del otro, es común que uno de los lados esté marcado de alguna forma. Resulta ser que los árabes usaban una flor. Con el tiempo el castellano adoptó azahar, para designar solo ciertas flores como las del naranjo y azar como sinónimo de aleatorio.
Empecemos, entonces imaginando que tenemos un dado de 6 caras, cada vez que arrojamos el dado solo es posible obtener un número entero del 1-6 es decir {1, 2, 3, 4, 5, 6}. Al arrojar el dado podemos obtener cualquier de estos números sin preferencia de uno sobre otro. Usando Python podemos programar un dado de 6 caras de la siguiente forma:
Al ejecutar la celda anterior repetidas veces podrán ver que en cada ejecución se obtiene un número (entero) distinto entre 1 y 6. Entender que está haciendo exactamente esta función no es del todo relevante, pero si es útil entender la idea general detrás de esta función. Veamos:
Las computadoras son en esencia deterministas. Es decir para una misma entrada la salida será siempre igual. Es como calcular \(\sqrt{4}\) el resultado será siempre \(2\). Esta consistencia es útil, en el funcionamiento de un desfibrilador automático, en un sistema de control aéreo, o en una app para reproducir música. Pero existen casos en donde necesitamos números aleatorios, por ejemplo en probabilidad y estadística, pero también otras áreas como cyber-seguridad. Para esos casos existen algoritmos que a partir de un valor inicial llamado semilla son capaces de producir una secuencia de valores, que si bien es determinista, a los fines prácticos tiene toda la pinta de aleatoria. Estos número se llaman pseudoaleatorios
En el caso de la función dado la semilla la generamos en la linea semilla = time.perf_counter_ns(), time.perf_counter_ns() es una función que mide el tiempo con precisión de nanosegundos. Cada vez que llamamos a dado ese valor será distinto. Luego en la última linea return semilla % 6 + 1 se calcula el resto de la división de la semilla por 6 y se le suma 1. Por ejemplo si la semilla fuese 12 el resto de dividir por 6 (12%6) sería 0, ya que \(\frac{12}{6}=2\). Pero si la semilla fuese 10 entonces el resto de dividir por 6 (10%6) sería 4.
Supongamos que ustedes, con justa razón, no me creen que dado realmente se comporta como un dado no trucado. Es decir, que todos los números tienen igual chance de salir. ¿Cómo podríamos hacer para evaluar esta posibilidad?
- Una posibilidad es consultar a los astros o los ángeles.
- Otra sería pensar mucho sobre el problema para luego quizá declararse agnóstico sobre la truquez no solo de nuestro dado digital si no de los dados en general y aún más sobre la posibilidad misma de acceder al conocimiento.
- Una tercera alternativa es recolectar datos y analizarlos, esta última es la opción preferida por quienes practican disciplinas científicas, en particular la estadística.
Usando Python podemos simular la recolección de datos de la siguiente forma.
def experimento(N=100):
# llamamos a `dado` N veces y guardamos los resultados en `muestra`
muestra = [dado() for i in range(N)]
# calculamos la proporción de veces que aparece cada valor en ` muestra` y lo imprimimos en pantalla
for i in range(1, 7):
print(f'{i}: {muestra.count(i)/N:.2g}')
experimento()1: 0.26
2: 0.13
3: 0.14
4: 0.1
5: 0.18
6: 0.19Los números en la primer columna son los posibles resultados. Los de la segunda columna corresponden con la frecuencia con la que aparece cada número. La frecuencia es la cantidad de veces que aparece cada uno de los posibles resultados dividido por N. Siendo N el total de veces que arrojamos el dado.
Hay al menos dos aspectos que vale resaltar en este ejemplo:
Cada vez que se ejecuta la celda anterior, es decir cada vez que realizamos el experimento, se obtiene un resultado distinto. Esta es precisamente la razón de usar dados en juegos de azar, cada vez que los arrojamos obtenemos un número que no podemos predecir con absoluta certeza.
Si arrojamos muchas veces un mismo dado la capacidad de predecir cada una de las tiradas no mejora. En ese sentido recolectar datos no nos ayuda. Pero recolectar datos si mejora la capacidad de predecir el listado de las frecuencias, de hecho la capacidad mejora de forma consistente al aumentar
N. Para un valor deN=10000verás que las frecuencias obtenidas son aproximadamente \(0.17\) y resulta ser que \(0.17 \approx \frac{1}{6}\) que es lo que esperado si cada número en el dado tuviera la misma posibilidad de aparecer.
Estas dos observaciones no están restringidas a los dados y los juegos de azar. Si nos pesáramos todos los días obtendríamos distintos valores ya que el peso tiene relación con la cantidad de comida que ingerimos, el agua que tomamos, cuantos orinamos y defecamos, la precisión de la balanza, la ropa que usamos. Por todo ello una sola medida podría no ser representativa de nuestro peso. Es cierto que todas estas variaciones podrían ser demasiado pequeñas para nuestro propósito y podríamos considerarlas irrelevantes, pero eso es adelantarse a nuestra discusión. El punto importante en este momento es que los datos van acompañados de incertidumbre, gran parte de la estadística tiene que ver con métodos y prácticas para lidiar con esa incertidumbre.
1.2 Probabilidades
Es posible utilizar probabilidades para asignar números precisos a la incertidumbre de lo que observamos, medimos, modelamos, etc. Por ello Joseph K. Blitzstein y Jessica Hwang dicen La matemática es la lógica de la certeza mientras que la probabilidad es la lógica de la incerteza.
Entender como pensar en presencia de incerteza es central en Estadística y Ciencia de Datos y prácticamente en cualquier disciplina científica. Esta incerteza proviene de diversas fuentes, incluyendo datos incompletos, errores de medición, límites de los diseños experimentales, dificultad de observar ciertos eventos, aproximaciones, etc.
A continuación veremos una breve introducción a conceptos centrales en probabilidad a partir de lo cuales podremos comprender mejor los fundamentos del modelado Bayesiano. Para quienes tengan interés en profundizar en el tema recomiendo leer el libro Introduction to Probability de Joseph K. Blitzstein y Jessica Hwang.
El marco matemático para trabajar con las probabilidades se construye alrededor de los conjuntos matemáticos.
El espacio muestral \(\mathcal{X}\) es el conjunto de todos los posibles resultados de un experimento. Un evento \(A\) es un subconjunto de \(\mathcal{X}\). Decimos que \(A\) ha ocurrido si al realizar un experimento obtenemos como resultado \(A\). Si tuviéramos un típico dado de 6 caras tendríamos que:
\[\mathcal{X} = \{1, 2, 3, 4, 5, 6\} \tag {0.0}\]
Podemos definir al evento \(A\) como:
\[A = \{2\} \tag {0.1}\]
Si queremos indicar la probabilidad del evento \(A\) escribimos \(P(A=2)\) o de forma abreviada \(P(A)\).
\(P(A)\) puede tomar cualquier valor en el intervalo comprendido entre 0 y 1 (incluidos ambos extremos), en notación de intervalos esto se escribe como [0, 1]. Es importante notar que no es necesariamente cierto que \(P(A) = \frac{1}{6}\).
Al definir el evento \(A\) podemos usar más de un elemento de \(\mathcal{X}\). Por ejemplo, números impares \(A = \{1, 3, 5\}\), o números mayores o iguales a 4 \(A = \{4,5,6\}\), o \(A = \{1,2,4,6\}\). Para cualquier problema concreto la definición de un evento como \(A\) dependerá directamente del problema.
Resumiendo, los eventos son subconjuntos de un espacio muestral definido adecuadamente y las probabilidades son números entre 0 y 1 asociados a la posibilidad que esos eventos ocurran. Si el evento es imposible entonces la probabilidad de ese evento será exactamente 0, si en cambio el evento sucede siempre entonces la probabilidad de ese evento será de 1. Todos los valores intermedios reflejan grados de incerteza. Desde este punto de vista es natural preguntarse cual es la probabilidad que la masa de Saturno sea \(x\) kg, o hablar sobre la probabilidad de lluvia durante el 25 de Mayo de 1810, o la probabilidad de que mañana amanezca.
Esta interpretación del concepto de probabilidad como medida de incertidumbre se suele llamar interpretación Bayesiana o subjetiva. Existen otras interpretaciones, por ej según la interpretación frecuentista una probabilidad es la proporción de veces que un evento sucedería si pudiéramos repetir infinitas veces una observación bajo las mismas condiciones. Es importante destacar que estas interpretaciones son andamiajes conceptuales, interpretaciones filosóficas. El aparato matemático que describe las probabilidades es uno solo y no distingue entre estas u otras interpretaciones.
1.3 Probabilidad condicional
Una probabilidad condicional es simplemente la probabilidad de un evento dado que conocemos que otro evento ha sucedido. Al preguntar cual es la probabilidad que llueva dado que está nublado estamos planteando una probabilidad condicional.
Dado dos eventos \(A\) y \(B\) siendo \(P(B) > 0\), la probabilidad de \(A\) dado \(B\) es definida como:
\[ P(A \mid B) \triangleq \frac{P(A, B)}{P(B)} \tag{0.2} \]
\(P(A, B)\) es la probabilidad conjunta, es decir la probabilidad que suceda el evento \(A\) y que ocurra el evento \(B\), también se suele escribir como \(P(A \cap B)\), el símbolo \(\cap\) indica intersección de conjuntos.
\(P(A \mid B)\) es lo que se conoce como probabilidad condicional, y es la probabilidad de que ocurra el evento A condicionada por el conocimiento que B ha ocurrido. Por ejemplo la probabilidad que una vereda esté mojada puede ser diferente de la probabilidad que esa vereda esté mojada dado que está lloviendo.
Una probabilidad condicional se puede visualizar como la reducción del espacio muestral. Para ver esto de forma más clara vamos a usar una figura adaptada del libro Introduction to Probability de Joseph K. Blitzstein y Jessica Hwang. En ella se puede ver como pasamos de tener los eventos \(A\) y \(B\) en el espacio muestral \(\mathcal{X}\), en el primer cuadro, a tener \(P(A \mid B)\) en el último cuadro donde el espacio muestral se redujo de \(\mathcal{X}\) a \(B\).
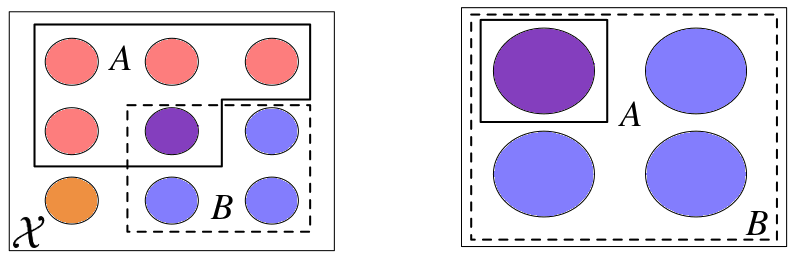
El concepto de probabilidad condicional está en el corazón de la estadística y es central para pensar en como debemos actualizar el conocimiento que tenemos de un evento a la luz de nuevos datos. Veremos más sobre esto en los próximos capítulos. Por ahora dejamos este tema con la siguiente aclaración. Desde el punto de vista práctico, todas las probabilidades son condicionales (respecto de algún supuesto o modelo) aún cuando no lo expresemos explícitamente, no existen probabilidades sin contexto.
1.4 Distribuciones de probabilidad
A nosotros en general no nos interesará calcular la probabilidad de eventos concretos sino que nos interesará calcular distribuciones de probabilidad. Es decir, en vez de calcular la probabilidad de obtener el número 5 al arrojar un dado, nos interesará averiguar el listado de todas las posibilidades del dado (1 al 6). Una vez obtenido este listado podremos hacer preguntas como ¿Cuál es la probabilidad de obtener el número 5?, ¿Cuánto más probable es obtener número pares que impares? u otras preguntas relacionadas. El nombre formal de este listado es distribución de probabilidad.
En el ejemplo del dado obtuvimos una distribución de probabilidad empírica, es decir una distribución calculada a partir de datos. Pero también existen distribuciones teóricas, las cuales son centrales en estadística entre otras razones por que permiten construir modelos probabilistas.
Las distribuciones de probabilidad teóricas tienen formulas matemáticas precisas, de forma similar a como las circunferencias tienen una definición matemática precisa.
Una circunferencia es el lugar geométrico de los puntos de un plano que equidistan a otro punto llamado centro.
Dado el parámetro radio una circunferencia queda perfectamente definida. Si necesitáramos ubicar la circunferencia respecto de otros objetos en el plano, necesitaríamos además las coordenadas del centro, pero omitamos ese detalle por el momento.
Veamos el siguiente ejemplo:
def dibuja_circ(radio):
_, ax = plt.subplots(figsize=(2, 2))
x = np.linspace(0, 2*np.pi, 100)
ax.plot(radio*np.cos(x), radio*np.sin(x))
ax.set_xlim(-11, 11)
ax.set_ylim(-11, 11)
ax.set_xticks([])
ax.set_yticks([])
interact(dibuja_circ,
radio=ipyw.FloatSlider(min=0.5, max=10, step=0.5, value=2.));Podríamos decir que no existe una sola circunferencia, sino una familia de circunferencias donde cada miembro se diferencia del resto solo por el valor del parámetro radio, ya que una vez definido este parámetro la circunferencia queda definida.
De forma similar las distribuciones de probabilidad vienen en familias cuyos miembros quedan definidos por uno o más parámetros. Es común que los nombres de los parámetros de las distribuciones de probabilidad sean letras del alfabeto griego, aunque esto no es siempre así.
En el siguiente ejemplo tenemos una distribución de probabilidad que podríamos usar para representar un dado y que es controlada por dos parámetros \(\alpha\) y \(\beta\):
def dist_dado(α, β):
n = 5
x = np.arange(0, 6)
dist_pmf = special.binom(n, x) * (special.beta(x+α, n-x+β) / special.beta(α, β))
plt.vlines(x, 0, dist_pmf, colors='C0', lw=4)
plt.ylim(0, 1)
plt.xticks(x, x+1)
interact(dist_dado,
α=ipyw.FloatSlider(min=0.5, max=10, step=0.5, value=1),
β=ipyw.FloatSlider(min=0.5, max=10, step=0.5, value=1));Esta distribución (o familia de distribuciones) se llama beta-binomial, si cambiamos los parámetros \(\alpha\) y \(\beta\) la “forma particular” de la distribución cambiará, podemos hacer que sea plana o concentrada más hacia el medio o hacia uno u otro extremo, etc. Así como el radio de la circunferencia debe ser positivo, los parámetros \(\alpha\) y \(\beta\) también están restringidos a ser positivos.
1.5 Variables aleatorias discretas y distribuciones de probabilidad
Una variable aleatoria es una función que asocia números reales \(\mathbb{R}\) con un espacio muestral. Continuando con el ejemplo del dado si los eventos de interés fuesen los números del dado entonces el mapeo es simple, ya que asociamos ⚀ con el número 1, ⚁ con el 2, etc. Si tuviéramos dos dados podríamos definir una variable aleatoria \(S\) como la suma de ambos dados. En este caso la variable aleatoria tomaría los valores \(\{2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12\}\) y si los dados no están trucados la distribución de probabilidad de la variable sería
.svg)
Otra variable aleatoria podría ser \(C\) cuyo espacio muestral es \(\{rojo, verde, azul\}\). Si los eventos de interés fuesen rojo, verde, azul, entonces podríamos codificarlos de la siguiente forma:
C(rojo) = 0, C(verde)=1, C(azul)=2
Esta codificación es útil ya que en general es más fácil operar con números que con cadenas (strings), ya sea que las operaciones las hagamos manualmente o con una computadora.
Una variable es aleatoria en el sentido de que en cada experimento es posible obtener un evento distinto sin que la sucesión de eventos siga un patrón determinista. Por ejemplo si preguntamos cual es el valor de \(C\) tres veces seguida podríamos obtener, rojo, rojo, azul o quizá azul, verde, azul, etc.
Cuando se habla de variables aleatorias, es común que surjan algunos malos entendidos:
- La variable NO puede tomar cualquier valor imaginable, en el ejemplo de los colores solo son posibles 3 valores. En el ejemplo del dado solo 6 valores son posibles.
- Aleatorio NO implica que todos los eventos tengan igual probabilidad.
bien podría darse el siguiente ejemplo:
\[P(C=rojo) = \frac{1}{2}, P(C=verde) = \frac{1}{4}, P(C=azul) = \frac{1}{4}\]
La equiprobabilidad de los eventos es solo un caso especial.
Una variable aleatoria discreta es una variable que puede tomar valores discretos, los cuales forman un conjunto finito (o infinito numerable). En nuestro ejemplo \(C\) es discreta ya que solo puede tomar 3 valores, sin posibilidad de valores intermedios entre ellos, no es posible obtener el valor verde-rojizo! \(S\) también es discreta y como ya dijimos solo es posible obtener los enteros en el intervalo [2-12].
Si en vez de “rótulos” hubiéramos usado el espectro continuo de longitudes onda visibles otro sería el caso, ya que podríamos haber definido a \(C=\{400 \text{ nm} ... 750\text{ nm}\}\) y en este caso no hay dudas que sería posible obtener un valor a mitad de camino entre rojo (\(\approx 700 \text{ nm}\)) y verde (\(\approx 530 \text{ nm}\)), de hecho podemos encontrar infinitos valores entre ellos. Este sería el ejemplo de una variable aleatoria continua.
Una variable aleatoria tiene una lista asociada con la probabilidad de cada evento. El nombre formal de esta lista es distribución de probabilidad, en el caso particular de variables aleatorias discretas se le suele llamar también función de masa de probabilidad (o pmf por su sigla en inglés). Es importante destacar que la \(pmf\) es una función que devuelve probabilidades, por lo tanto siempre obtendremos valores comprendidos entre [0, 1] y cuya suma total (sobre todos los eventos) dará 1.
En principio nada impide que uno defina su propia distribución de probabilidad. Pero a lo largo de los últimos 3 siglos se han identificado y estudiado muchas distribuciones de probabilidad que dado su utilidad se les ha asignado “nombre propio”, por lo que conviene saber sobre su existencia. El siguiente listado no es exhaustivo ni tiene como propósito que memoricen las distribuciones y sus propiedades, solo que ganen cierta familiaridad con las mismas. Si en el futuro necesitan utilizar alguna \(pmf\) pueden volver a esta notebook o pueden revisar Wikipedia donde encontrarán información muy completa.
En las siguientes gráficas las alturas de los puntos azules indican la probabilidad de cada valor de \(x\). Se indican, además, la media (\(\mu\)) y desviación estándar (\(\sigma\)) de las distribuciones, es importante destacar que estos valores NO son calculados a partir de datos, de hecho no hay datos solo objetos matemáticos. Los valores de \(\mu\) y \(\sigma\) son propiedades matemáticas de las distribuciones, de la misma forma que el área de un círculo es una propiedad que queda definida una vez que fijamos el parámetro radio.
1.5.1 Distribución uniforme discreta
Es una distribución que asigna igual probabilidad a un conjunto finitos de valores, su \(pmf\) es:
\[p(k \mid a, b)={\frac {1}{b - a + 1}} = \frac{1}{n}\tag {0.3}\]
Para valores de \(k\) en el intervalo [a, b], fuera de este intervalo \(p(k) = 0\), donde \(n=b-a+1\) es la cantidad total de valores que puede tomar \(k\).
Podemos usar esta distribución para modelar, por ejemplo un dado no cargado.
dist = pz.DiscreteUniform(lower=1, upper=6)
# PreliZ usa "plot_pdf" tanto para distribuciones discretas como continuas
ax = dist.plot_pdf(moments="md", support=(0, 7))
ax.set_xlabel('x')
ax.set_ylabel('p(x)', rotation=0, labelpad=25);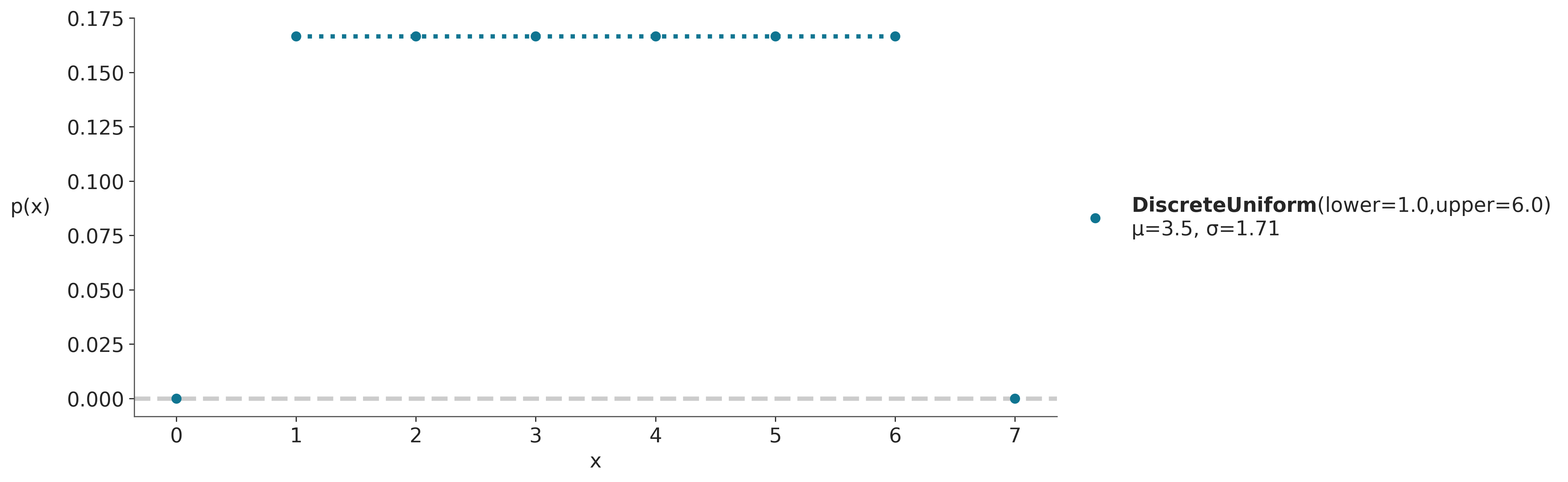
En la figura anterior la altura de cada punto indica la probabilidad de cada evento, usamos puntos y lineas punteadas para remarcar que la distribución es discreta. En este ejemplo en concreto la distribución uniforme está definida en el intervalo [1, 6]. Por lo tanto todos los valores menores a 1 y mayores a 6 tienen probabilidad 0. Al ser una distribución uniforme todos los puntos tienen la misma altura y esa altura es \(\frac{1}{6}\).
Los parámetros de la distribución discreta uniforme son dos: * El límite inferior representado con la letra “a” en la expresión 0.3 * El límite superior representado con la letra “b” en la expresión 0.3
Si cambiamos los parámetros la “forma particular” de la distribución cambiará (prueben por ejemplo reemplazar upper=6 en el bloque de código anterior por upper=4). Es por ello que se suele hablar de familia de distribuciones, cada miembro de esa familia es una distribución con una combinación particular y válida de parámetros. Por ejemplo la familia de distribuciones discretas uniforme es aquella indicada en la expresión 0.3, siempre y cuando: * \(a < b\) * \(a \in \mathbb {Z}\) * \(b \in \mathbb {Z}\)
donde \(\mathbb {Z}\) es el conjunto de los números enteros.
Es común vincular los parámetros con cantidades que tienen sentido físico por ejemplo en un dado de 6 caras tiene sentido que \(a=1\) y \(b=6\). A veces desconocemos los valores de los parámetros y es nuestro trabajo utilizar datos y métodos estadísticos para encontrar esos valores.
1.5.2 Distribución binomial
Es la distribución de probabilidad discreta que cuenta el número de éxitos en una secuencia de \(n\) ensayos de Bernoulli (experimentos si/no) independientes entre sí, con una probabilidad fija \(p\) de ocurrencia del éxito entre los ensayos. Cuando \(n=1\) esta distribución se reduce a la distribución de Bernoulli.
\[p(x \mid n,p) = \frac{n!}{x!(n-x)!}p^x(1-p)^{n-x} \tag {0.4}\]
El término \(p^x(1-p)^{n-x}\) indica la probabilidad de obtener \(x\) éxitos en \(n\) intentos. Este término solo tiene en cuenta el número total de éxitos obtenidos pero no la secuencia en la que aparecieron. El primer término conocido como coeficiente binomial calcula todas las posibles combinaciones de \(n\) en \(x\), es decir el número de subconjuntos de \(x\) elementos escogidos de un conjunto con \(n\) elementos.

1.5.3 Distribución de Poisson
Es una distribución de probabilidad discreta que expresa la probabilidad que \(x\) eventos sucedan en un intervalo fijo de tiempo (o espacio o volumen) cuando estos eventos suceden con una tasa promedio \(\mu\) y de forma independiente entre si. Se la utiliza para modelar eventos con probabilidades pequeñas (sucesos raros) como accidentes de tráfico o decaimiento radiactivo.
\[ p(x \mid \mu) = \frac{\mu^{x} e^{-\mu}}{x!} \tag {0.5} \]
donde x es el número de eventos \((x =0,1,2,\ldots)\)
Tanto la media como la varianza de esta distribución están dadas por \(\mu\).
A medida que \(\mu\) aumenta la distribución de Poisson se aproxima a una distribución Gaussiana (aunque sigue siendo discreta). La distribución de Poisson tiene estrecha relación con otra distribución de probabilidad, la binomial. Una distribución binomial puede ser aproximada con una distribución de Poisson, cuando \(n >> p\), es decir, cuando la cantidad de “éxitos” (\(p\)) es baja respecto de la cantidad de “intentos” (p) entonces \(\text{Poisson}(np) \approx \text{Binon}(n, p)\). Por esta razón la distribución de Poisson también se conoce como “ley de los pequeños números” o “ley de los eventos raros”. Ojo que esto no implica que \(\mu\) deba ser pequeña, quien es pequeño/raro es \(p\) respecto de \(n\).
dist = pz.Poisson(mu=2.3) # número de veces que se espera que ocurra un evento.
# PreliZ conoce cuales son los límites de una distribución y los usa al grafica
# Para distribuciones que no tienen límites PreliZ usa los cuantiles 0.001 y 0.999
# En el caso de la distribución de Poisson, el gráfico va de 0 a el cuantil 0.999
ax = dist.plot_pdf(moments="md")
ax.set_xlabel('x')
ax.set_ylabel('p(x)', rotation=0, labelpad=25);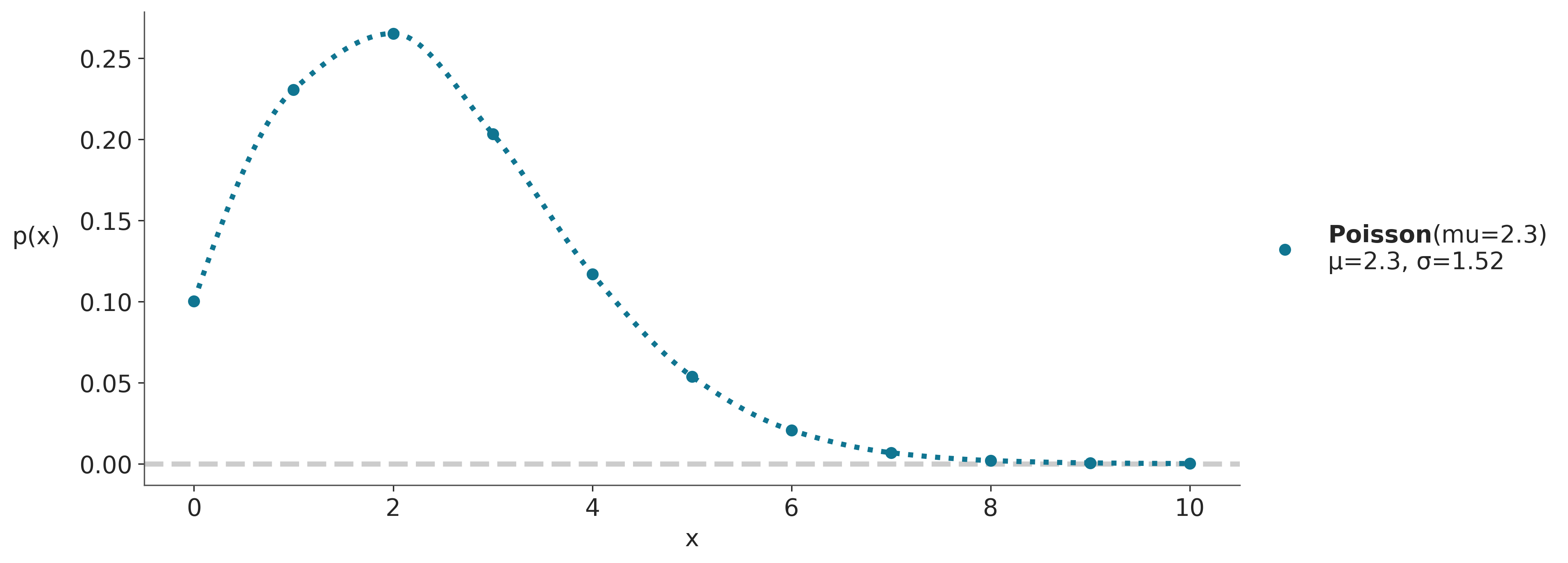
1.6 Variables aleatorias y distribuciones de probabilidad continuas
Hasta ahora hemos visto variables aleatorias discretas y distribuciones de masa de probabilidad. Existe otro tipo de variable aleatoria que son muy usadas y son las llamadas variables aleatorias continuas, ya que toman valores en \(\mathbb{R}\).
La diferencia más importante entre variables aleatoria discretas y continuas es que para las continuas \(P(X=x) = 0\), es decir, la probabilidad de cualquier valor es exactamente 0.
En las gráficas anteriores, para variables discretas, es la altura de los puntos lo que define la probabilidad de cada evento. Si sumamos todas las alturas siempre obtenemos 1. En una distribución continua no tenemos una cantidad finita de puntos que sumar, en cambio tenemos una cantidad infinita de puntos que definen una curva continua, la altura de esa curva es la densidad de probabilidad. Si queremos averiguar cuanto más probable es el valor \(x_1\) respecto de \(x_2\) basta calcular:
\[\frac{pdf(x_1)}{pdf(x_2)} \tag {0.6}\]
Donde \(pdf\) es la función de densidad de probabilidad (por su sigla en inglés). Y es análoga a la \(pmf\) que vimos para variables discretas. Una diferencia importante es que la \(pdf(x)\) puede devolver mayores a 1. Para obtener una probabilidad a partir de una \(pdf\) debemos integrar en un intervalo dado, ya que es el área bajo la curva y no la altura lo que nos da la probabilidad, es decir es esta integral la que debe dar entre 0 y 1.
\[P(a \lt X \lt b) = \int_a^b pdf(x) dx\]
En muchos textos es común usar \(p\) para referirse a la probabilidad de un evento en particular o a la \(pmf\) o a la \(pdf\), esperando que la diferencia se entienda por contexto.
A continuación veremos varias distribuciones continuas.
1.6.1 Distribución uniforme
Aún siendo simple, la distribución uniforme es muy usada en estadística, por ejemplo para representar nuestra ignorancia sobre el valor que pueda tomar un parámetro.
\[ p(x \mid a,b)=\begin{cases} \frac{1}{b-a} & para\ a \le x \le b \\ 0 & \text{para el resto} \end{cases} \tag {0.7} \]
dist = pz.Uniform(0, 1)
x_rvs = dist.rvs(500) # muestrear 500 valores de la distribución
ax = dist.plot_pdf(moments="md")
ax.hist(x_rvs, density=True)
ax.set_xlabel('x')
ax.set_ylabel('pdf(x)', rotation=0, labelpad=25);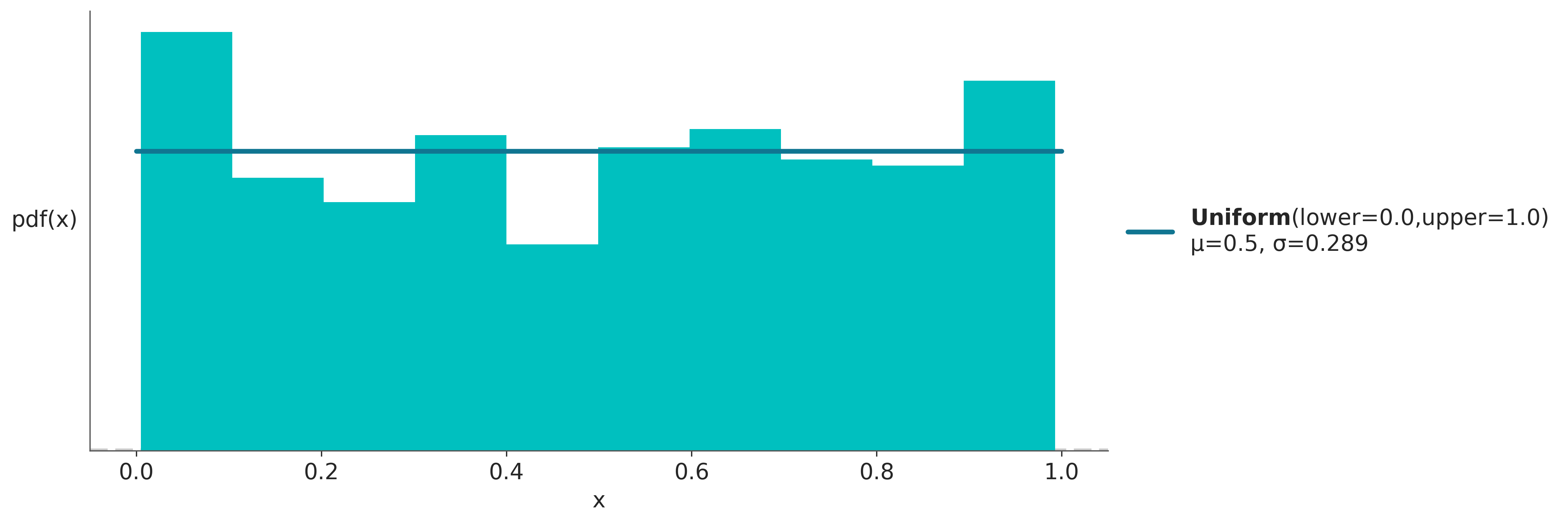
En la figura anterior la curva azul representa la \(pdf\). La \(pdf\) es un objeto matemático que da la descripción exacta de la distribución, no es algo que exista en la realidad si no una construcción matemática que es útil para aproximar o modelar algún aspecto de la realidad. La \(pdf\) es como las esferas, las esferas no existen pero pueden ser útiles para describir objetos tales como pelotas, planetas, átomos, aún cuando ni las pelotas, planetas o átomos sean esferas.
El histograma en turquesa representa una muestra tomadas a partir de la \(pdf\) representada en azul. A diferencia de la curva azul, que es un objeto (matemático) concreto. Una muestra es aleatoria. Cada vez que ejecutemos la celda anterior la curva azul será la misma pero el histograma cambiará.
Una aclaración antes de continuar. Los histogramas no son lo mismo que los gráficos de barras. Los histogramas son una forma de representación visual de datos que usa barras a fin de aproximar una distribución continua. Si bien la cantidad de barras es discreta, la distribución que intenta aproximar es continua, es por ello que las barras se dibujan de forma contigua, mientras que en los gráficos de barras (que representan distribuciones discretas) las barras se dibujan espaciadas.
Luego de estas aclaraciones continuemos con otras distribuciones de probabilidad continuas.
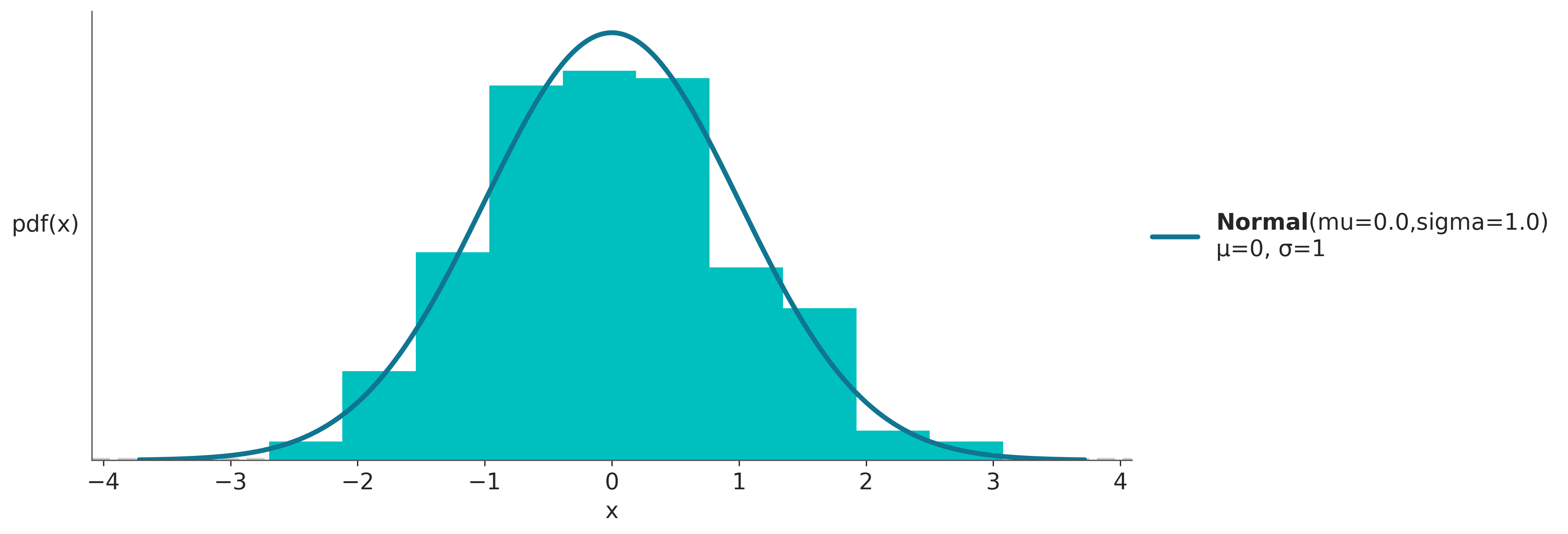
1.6.2 Distribución Gaussiana (o normal)
Es quizá la distribución más conocida. Por un lado por que muchos fenómenos pueden ser descriptos (aproximadamente) usando esta distribución. Por otro lado por que posee ciertas propiedades matemáticas que facilitan trabajar con ella de forma analítica. Es por ello que muchos de los resultados de la estadística se basan en asumir una distribución Gaussiana.
La distribución Gaussiana queda definida por dos parámetros, la media \(\mu\) y la desviación estándar \(\sigma\). Una distribución Gaussiana con \(\mu = 0\) y \(\sigma = 1\) es conocida como la distribución Gaussiana estándar.
\[ p(x \mid \mu,\sigma) = \frac{1}{\sigma \sqrt{ 2 \pi}} e^{ - \frac{ (x - \mu)^2 } {2 \sigma^2}} \tag {0.8} \]
1.6.3 Distribución t de Student
Históricamente esta distribución surgió para estimar la media de una población normalmente distribuida cuando el tamaño de la muestra es pequeño. En estadística Bayesiana su uso más frecuente es el de generar modelos robustos a datos aberrantes.
\[p(x \mid \nu,\mu,\sigma) = \frac{\Gamma(\frac{\nu + 1}{2})}{\Gamma(\frac{\nu}{2})\sqrt{\pi\nu}\sigma} \left(1+\frac{1}{\nu}\left(\frac{x-\mu}{\sigma}\right)^2\right)^{-\frac{\nu+1}{2}} \tag {0.9} \]
donde \(\Gamma\) es la función gamma y donde \(\nu\) es un parámetro llamado grados de libertad en la mayoría de los textos aunque también se le dice grado de normalidad, ya que a medida que \(\nu\) aumenta la distribución se aproxima a una Gaussiana. En el caso extremo de \(\lim_{\nu\to\infty}\) la distribución es exactamente igual a una Gaussiana.
En el otro extremo, cuando \(\nu=1\), (aunque en realidad \(\nu\) puede tomar valores por debajo de 1) estamos frente a una distribución de Cauchy. Es similar a una Gaussiana pero las colas decrecen muy lentamente, eso provoca que en teoría esta distribución no poseen una media o varianza definidas. Es decir, es posible calcular a partir de un conjunto de datos una media, pero si los datos provienen de una distribución de Cauchy, la dispersión alrededor de la media será alta y esta dispersión no disminuirá a medida que aumente el tamaño de la muestra. La razón de este comportamiento extraño es que en distribuciones como la Cauchy están dominadas por lo que sucede en las colas de la distribución, contrario a lo que sucede por ejemplo con la distribución Gaussiana.
Para esta distribución \(\sigma\) no es la desviación estándar, que como ya se dijo podría estar indefinida, \(\sigma\) es la escala. A medida que \(\nu\) aumenta la escala converge a la desviación estándar de una distribución Gaussiana.

1.6.4 Distribución exponencial
La distribución exponencial se define solo para \(x > 0\). Esta distribución se suele usar para describir el tiempo que transcurre entre dos eventos que ocurren de forma continua e independiente a una taza fija. El número de tales eventos para un tiempo fijo lo da la distribución de Poisson.
\[ p(x \mid \lambda) = \lambda e^{-\lambda x} \tag {0.10} \]
La media y la desviación estándar de esta distribución están dadas por \(\frac{1}{\lambda}\)

1.6.5 Distribución de Laplace
También llamada distribución doble exponencial, ya que puede pensarse como una distribución exponencial “más su imagen especular”. Esta distribución surge de medir la diferencia entre dos variables exponenciales (idénticamente distribuidas).
\[p(x \mid \mu, b) = \frac{1}{2b} \exp \left\{ - \frac{|x - \mu|}{b} \right\} \tag {0.11}\]

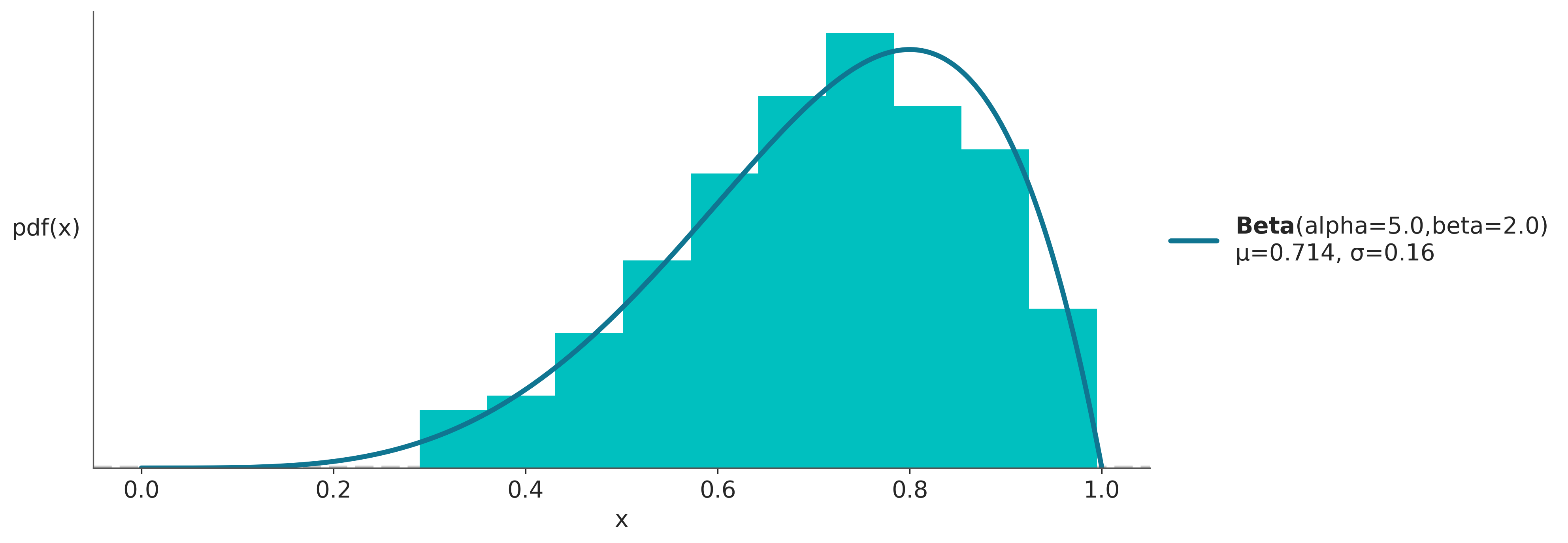
1.6.6 Distribución Beta
Es una distribución definida en el intervalo [0, 1]. Se usa para modelar el comportamiento de variables aleatorias limitadas a un intervalo finito. Es útil para modelar proporciones o porcentajes.
\[ p(x \mid \alpha, \beta)= \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\, x^{\alpha-1}(1-x)^{\beta-1} \tag {0.12} \]
El primer término es simplemente una constante de normalización que asegura que la integral de la pdf de 1. \(\Gamma\) es la función gamma. Cuando \(\alpha=1\) y \(\beta=1\) la distribución beta se reduce a la distribución uniforme.
Si queremos expresar la distribución beta en función de la media y la dispersión alrededor de la media podemos hacerlo de la siguiente forma.
\[\alpha = \mu \kappa\] \[\beta = (1 − \mu) \kappa\]
Siendo \(\mu\) la media y \(\kappa\) una parámetro llamado concentración a media que \(\kappa\) aumenta la dispersión disminuye. Nótese, además que \(\kappa = \alpha + \beta\).
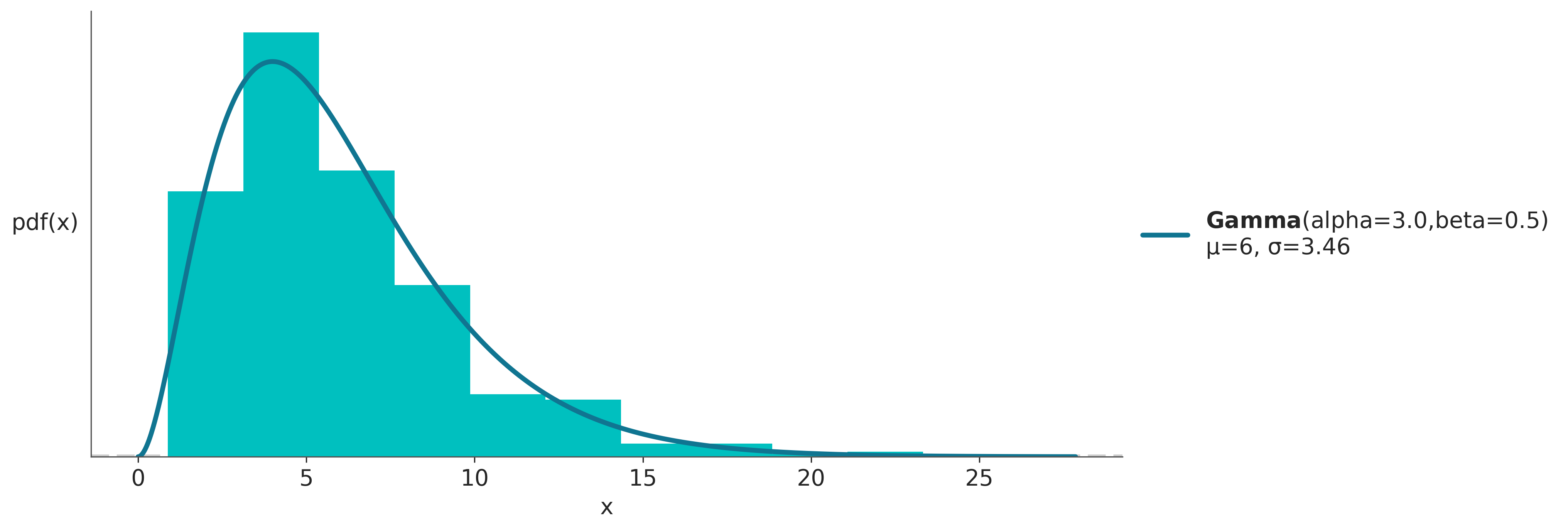
1.6.7 Distribución Gamma
Existen varias parametrizaciones para la distribución Gamma. Nosotros usaremos la siguiente:
\[ p(x \mid \alpha, \beta) = \frac{\beta^{\alpha}x^{\alpha-1}e^{-\beta x}}{\Gamma(\alpha)} \tag {0.14} \]
La distribución gamma se reduce a la exponencial cuando \(\alpha=1\).
Otra parametrización, disponible por ej en paquetes como PyMC y Preliz, es en términos de la media y la desviación estándar.
1.7 Valor esperado
El valor esperado (también conocido como esperanza o media) es un número que resume el centro de masa de una distribución. Por ejemplo, si \(X\) es una variable aleatoria discreta, podemos calcular su valor esperado como:
\[ \mathbb{E}[X] = \sum_{i=1}^n x_i P(X=x_i) \]
En estadística usualmente también queremos medir la dispersión de una distribución, por ejemplo, para representar la incertidumbre en torno a una estimación puntual como la media. Podemos hacer esto con la varianza, que también es un valor esperado:
\[ \mathbb{V}(X) = \mathbb{E}[(X - \mathbb{E}[X])^2] = \mathbb{E}[X^2] - \mathbb{E}[X]^2 \]
La varianza aparece naturalmente en muchos cálculos estadísticos. Sin embargo, para reportar los resultados de un análisis suele ser más útil la desviación estándar, que es la raíz cuadrada de la varianza. La principal ventaja es que esta última está en la mismas escala/unidades que la variable aleatoria.
El \(n\)-ésimo momento de una variable aleatoria \(X\) es \(\mathbb{E}[X^n]\), por lo que el valor esperado (media) y la varianza también se conocen como el primer y segundo momento de una distribución.
Una vez fijados los parámetros de una distribución de probabilidad. Es posible calcularle sus momentos, el primer momento es la media y el segundo la varianza. Es importante notar que estos valores son propiedades de la distribución y no propiedades de una muestra. Por ejemplo la media y varianza de una distribución Beta(4, 6) es \(0.4\) y \(\approx 0.22\), respectivamente
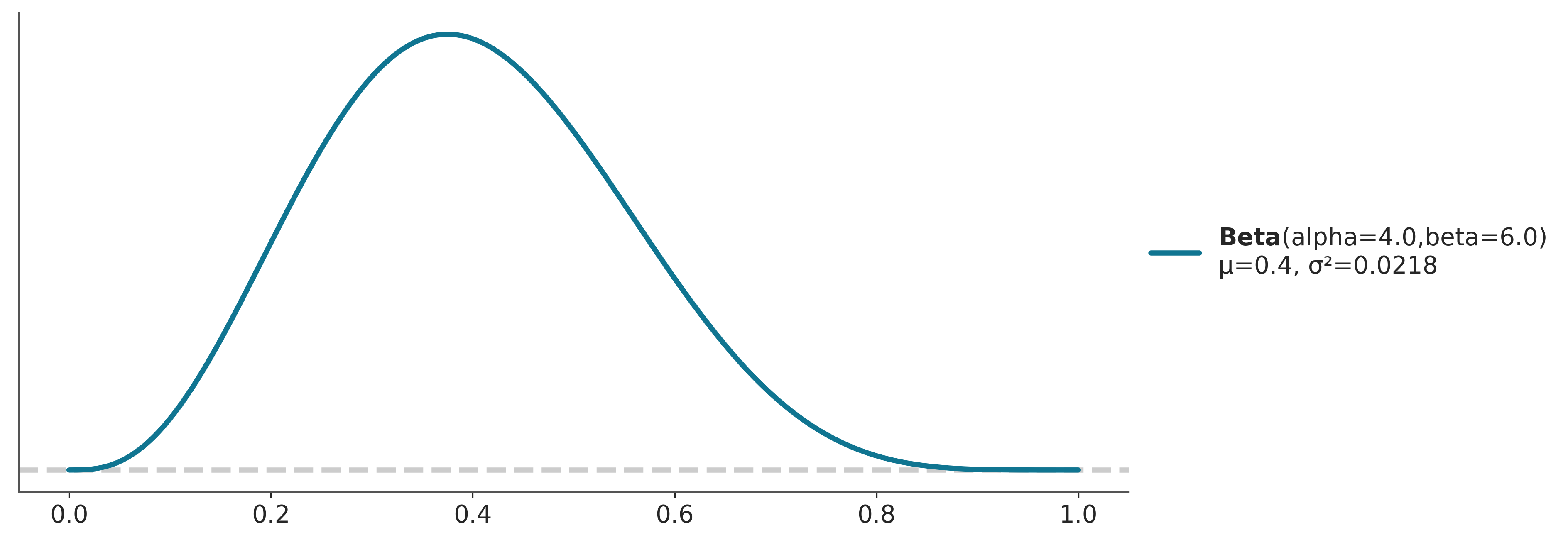
Existen otros momentos, el tercer momento se conoce como sesgo y habla de la asimetría de una distribución
pz.Beta(4, 4).plot_pdf(moments="s");
pz.Beta(4, 10).plot_pdf(moments="s");
pz.Beta(10, 4).plot_pdf(moments="s");
El cuarto momento, conocido como curtosis, nos habla del comportamiento de las colas o valores extremos. Suele calcularse de forma tal que de 0 para una Normal. Además las discusiones suelen centrarse en torno a distribuciones con curtosis positiva (como la distribución de Laplace o Student T con \(\nu > 4\)) por lo que es común hablar de exceso de curtosis. Mientras más grande la curtosis de una distribución más pesadas sus colas, es decir es más factible observar valores alejados de la media.

1.8 Distribución acumulada
La pdf (o la pmf) son formas comunes de representar y trabajar con variables aleatorias, pero no son las únicas formas posibles. Existen otras representaciones equivalentes. Por ejemplo la función de distribución acumulada (cdf en inglés). Al integrar una pdf se obtiene la correspondiente cdf, y al derivar la cdf se obtiene la pdf.
La integral de la pdf es llamada función de distribución acumulada (cdf):
\[ cdf(x) = \int_{-\infty}^{x} pdf(x) d(x) \tag {0.17} \]
En algunas situaciones se prefiere hablar de la función de supervivencia:
\[ S(x) = 1 - cdf \tag {0.18} \]
A continuación un ejemplo de la pdf y cdf para 4 distribuciones de la familia Gaussiana.
_, ax = plt.subplots(2, 1, figsize=(8, 6), sharex=True)
x_valores = np.linspace(-4, 4, 500)
valores = [(0., 1.), (0., 2.), (2., .5)]
for val in valores:
pz.Normal(*val).plot_pdf(ax=ax[0])
pz.Normal(*val).plot_cdf(ax=ax[1])
ax[1].get_legend().remove()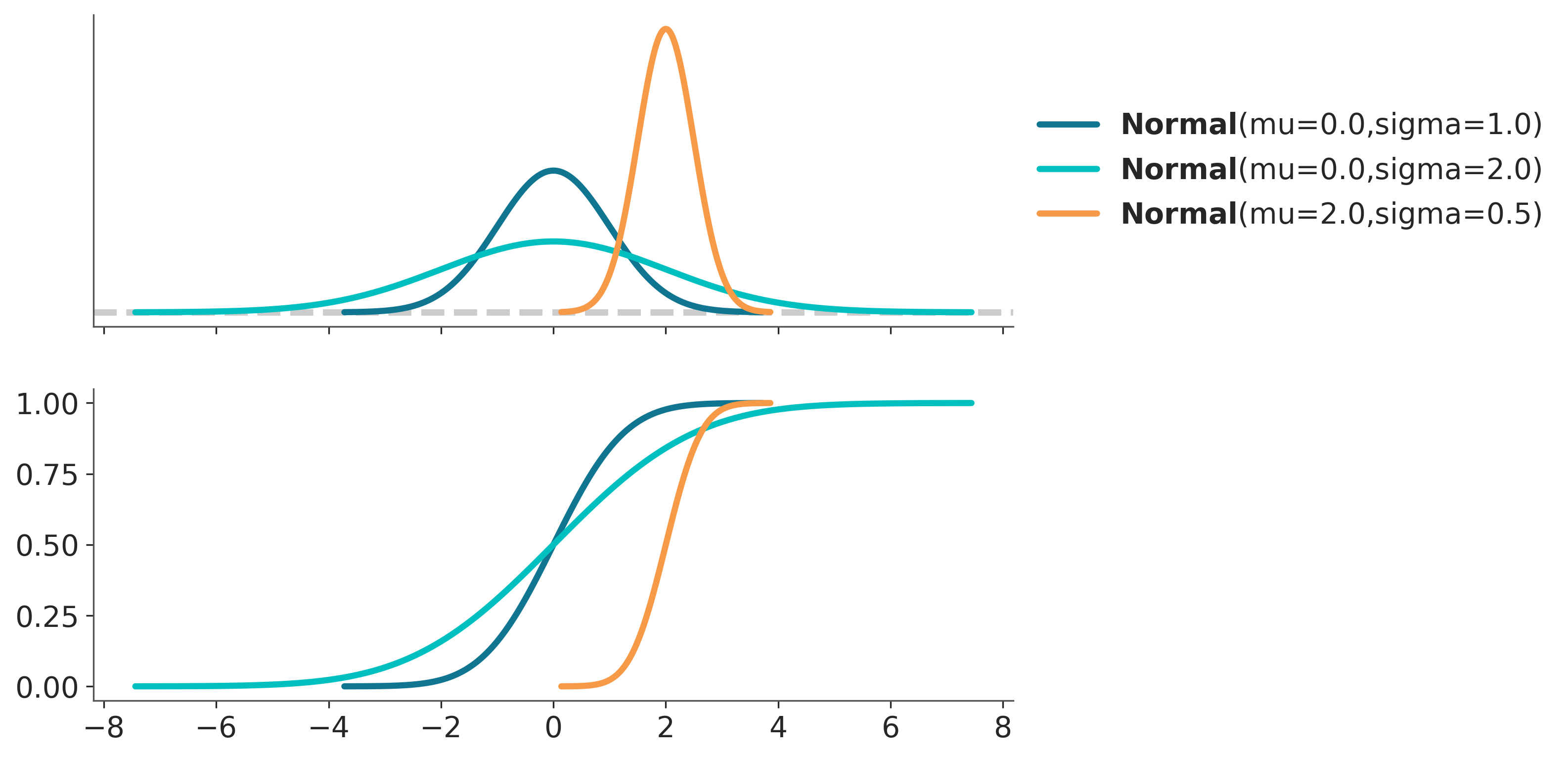
La siguiente figura tomada del libro Think Stats resume las relaciones entre la cdf, pdf y pmf.

1.9 Relación entre probabilidad conjunta, condicional y marginal
Al definir probabilidad condicional usamos la expresión 0.2. Ahora que ya estamos familiarizados con las distribuciones de probabilidad podemos representar gráficamente los tres términos en la expresión 0.2, tal como se muestra en la siguiente figura.

- Probabilidad conjunta \(p(A, B)\)
- Probabilidad marginal \(p(A)\) o \(p(B)\)
- Probabilidad condicional \(p(A \mid B)\)
Podemos re-escribir la expresión 0.2 de la siguiente manera:
\[ p(A, B) = p(A \mid B) {p(B)} \tag {0.15} \]
Es decir si tomo una probabilidad condicional y la evalúo para todos los valores de la cantidad condicionante (\(B\) en este caso), obtengo la distribución conjunta. Esto se puede ver gráficamente si pensamos que \(p(A \mid B)\) es una rebanada de p(A, B); rebanada que tomamos a la altura de \(B\). Si tomamos todas las rebanadas entonces obtendremos \(p(A, B)\).
Para obtener las probabilidades marginales, que se encuentran en los margenes 😉, podemos calcular algo similar:
\[ p(A) = \sum_B p(A, B) = \sum_B p(A \mid B) {p(B)} \tag {0.16} \]
Cambiando la sumatoria por una integral para distribuciones continuas.
1.10 Límites
Los dos teoremas más conocidos y usados en probabilidad son la ley de los grandes números y el teorema del límite central. Ambos nos dicen que le sucede a la media muestral a medida que el tamaño de la muestra aumenta.
1.10.1 La ley de los grandes números
El valor promedio calculado para una muestra converge al valor esperado (media) de dicha distribución. Esto no es cierto para algunas distribuciones como la distribución de Cauchy (la cual no tiene media ni varianza finita).
La ley de los grandes números se suele malinterpretar y dar lugar a la paradoja del apostador. Un ejemplo de esta paradoja es creer que conviene apostar en la lotería/quiniela a un número atrasado, es decir un número que hace tiempo que no sale. El razonamiento, erróneo, es que como todos los números tienen la misma probabilidad a largo plazo si un número viene atrasado entonces hay alguna especie de fuerza que aumenta la probabilidad de ese número en los próximo sorteos para así re-establecer la equiprobabilidad de los números.
tamaño_muestra = 200
muestras = range(1, tamaño_muestra)
dist = pz.Uniform(0, 1)
media_verdadera = dist.rv_frozen.stats('m')
for _ in range(3):
muestra = dist.rvs(tamaño_muestra)
media_estimada = [muestra[:i].mean() for i in muestras]
plt.plot(muestras, media_estimada, lw=1.5)
plt.hlines(media_verdadera, 0, tamaño_muestra, linestyle='--', color='k')
plt.ylabel("media", fontsize=14)
plt.xlabel("# de muestras", fontsize=14);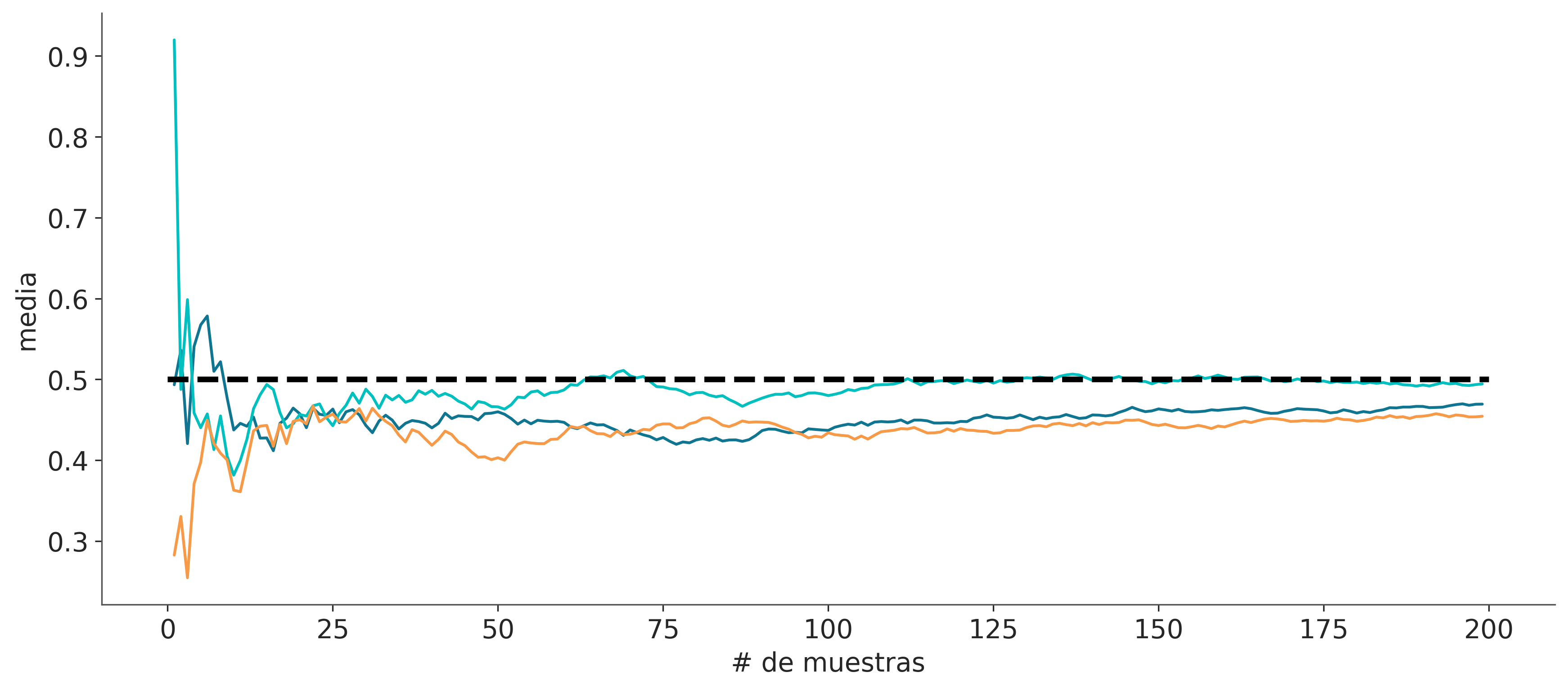
1.10.2 El teorema central del límite
El teorema central del límite (también llamado teorema del límite central) establece que si tomamos \(n\) valores (de forma independiente) de una distribución arbitraria la media \(\bar X\) de esos valores se distribuirá aproximadamente como una Gaussiana a medida que \({n \rightarrow \infty}\):
\[ \bar X_n \dot\sim \mathcal{N} \left(\mu, \frac{\sigma^2}{n}\right) \tag {0.19} \]
Donde \(\mu\) y \(\sigma^2\) son la media y varianza poblacionales.
Para que el teorema del límite central se cumpla se deben cumplir los siguientes supuestos:
- Las variables se muestrean de forma independiente
- Las variables provienen de la misma distribución
- La media y la desviación estándar de la distribución tiene que ser finitas
Los criterios 1 y 2 se pueden relajar bastante y aún así obtendremos aproximadamente una Gaussiana, pero del criterio 3 no hay forma de escapar. Para distribuciones como la distribución de Cauchy, que no posen media ni varianza definida este teorema no se aplica. El promedio de \(N\) valores provenientes de una distribución Cauchy no siguen una Gaussiana sino una distribución de Cauchy.
El teorema del límite central explica la prevalencia de la distribución Gaussiana en la naturaleza. Muchos de los fenómenos que estudiamos se pueden explicar como fluctuaciones alrededor de una media, o ser el resultado de la suma de muchos factores diferentes. Además, las Gaussianas son muy comunes en probabilidad, estadística y machine learning ya que que esta familia de distribuciones son más simples de manipular matemáticamente que muchas otras distribuciones.
A continuación vemos una simulación que nos muestra el teorema del límite central en acción.
iters = 2000
dist = pz.Exponential(1)
media, var = dist.rv_frozen.stats('mv')
_, ax = plt.subplots(2, 3)
for i, n in enumerate([1, 5, 100]):
sample = np.mean(dist.rvs((n, iters)), axis=0)
sd = (var/n)**0.5
x = np.linspace(media - 4 * sd, media + 4 * sd, 200)
ax[0, i].plot(x, pz.Normal(media, sd).pdf(x))
ax[0, i].hist(sample, density=True, bins=20)
ax[0, i].set_title('n = {}'.format(n))
osm, osr = stats.probplot(sample, dist=pz.Normal(media, sd), fit=False)
ax[1, i].plot(osm, osm)
ax[1, i].plot(osm, osr, 'o')
ax[1, 0].set_ylabel('observados')
ax[1, 1].set_xlabel('esperados');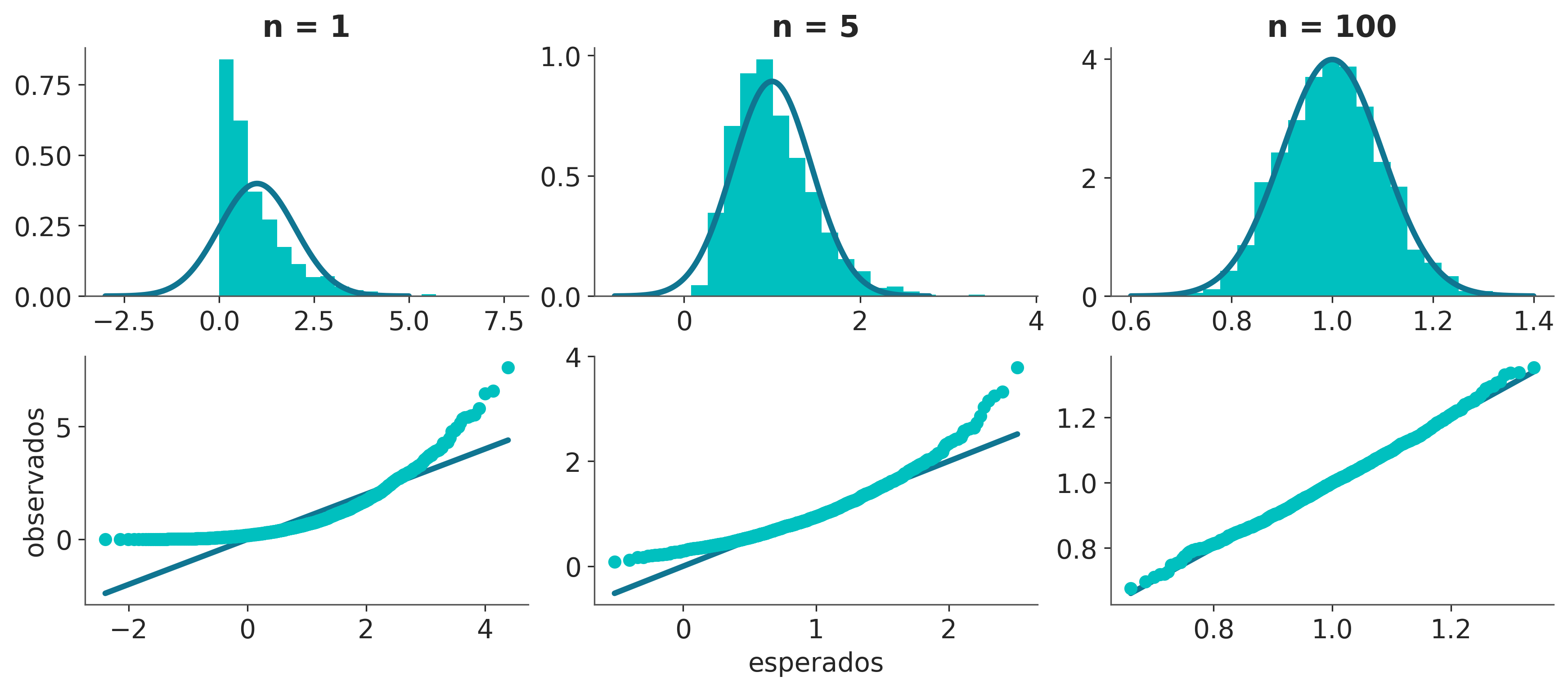
1.11 Ejercicios
De las siguientes expresiones cual(es) se corresponde(n) con el enunciado “la probabilidad de lluvia dado que es 25 de Mayo de 1810”?
- p(lluvia)
- p(lluvia | mayo)
- p(25 de Mayo de 1810 | lluvia)
- p(lluvia | 25 de Mayo de 1810 )
- p(lluvia, 25 de Mayo de 1810) / p(25 de Mayo de 1810)
Enuncie con palabras cada una de las expresiones del punto anterior.
Según la definición de probabilidad condicional
- Cual es el valor de \(P(A \mid A)\)?
- Cual es la probabilidad de \(P(A, B)\)?
- Cual es la probabilidad de \(P(A, B)\) en el caso especial que \(A\) y \(B\) sean independientes?
- Cuando se cumple que \(P(A \mid B) = P(A)\)?
- Es posible que \(P(A \mid B) > P(A)\), cuando?
- Es posible que \(P(A \mid B) < P(A)\), cuando?
Los siguientes ejercicios se deben realizar usando Python (y NumPy, PreliZ, Matplotlib) 1. Ilustrar que la distribución de Poisson se aproxima a una binomial cuando para la binomial \(n >> p\).
Para alguna de las distribuciones discretas presentadas en esta notebook verificar que la probabilidad total es 1.
Para alguna de las distribuciones continuas presentadas en esta notebook verificar que el área bajo la curva es 1.
Obtener la cdf a partir de la pdf (usar el método pdf provisto por PreliZ). La función
np.cumsumpuede ser de utilidad.Obtener la pdf a partir de la cdf (usar el método cdf provisto por PreliZ). La función
np.diffpuede ser de utilidad.Repetir la simulación para la ley de los grandes números para al menos 3 distribuciones de probabilidad. Para cada distribución probar más de un conjunto de parámetros.
Repetir la simulación para el teorema central del límite para al menos 3 distribuciones de probabilidad. Para cada distribución probar más de un conjunto de parámetros.
Mostrar en un gráfico que la media \(\bar X\) converge a \(\mu\) y la varianza converge a \(\frac{\sigma^2}{n}\) a medida que aumenta el tamaño de la muestra.